Discover and read the best of Twitter Threads about #statistics
Most recents (24)

Hi #EconTwitter!
Interested in the #econometrics of 𝐜𝐚𝐮𝐬𝐚𝐥 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞? 📈
Here's a thread with some great lecture notes, slides, and books on this topic - freely available on the web - which I've happily tweeted about! 📚🌐
Hope you'll find it useful!
Interested in the #econometrics of 𝐜𝐚𝐮𝐬𝐚𝐥 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞? 📈
Here's a thread with some great lecture notes, slides, and books on this topic - freely available on the web - which I've happily tweeted about! 📚🌐
Hope you'll find it useful!


𝐏𝐚𝐮𝐥 𝐆𝐨𝐥𝐝𝐬𝐦𝐢𝐭𝐡-𝐏𝐢𝐧𝐤𝐡𝐚𝐦'𝐬 (@paulgp) 𝐀𝐩𝐩𝐥𝐢𝐞𝐝 𝐄𝐦𝐩𝐢𝐫𝐢𝐜𝐚𝐥 𝐌𝐞𝐭𝐡𝐨𝐝𝐬
PhD-level slides covering econometrics, from causal inference to applied MachineLearning.
github.com/paulgp/applied…
PhD-level slides covering econometrics, from causal inference to applied MachineLearning.
github.com/paulgp/applied…
𝐏𝐞𝐧𝐠 𝐃𝐢𝐧𝐠'𝐬 (@pengding00) 𝐂𝐚𝐮𝐬𝐚𝐥 𝐢𝐧𝐟𝐞𝐫𝐞𝐧𝐜𝐞
Undergrad notes about the #statistics and #econometrics of causal inference.
arxiv.org/abs/2305.18793
Undergrad notes about the #statistics and #econometrics of causal inference.
arxiv.org/abs/2305.18793

Unveiling the shocking truth behind #Bihar's notorious nickname, #JungleRaaj. Brace yourself for a riveting thread 👇👇 that delves into the tumultuous history.
#JungleRaaj, the dark legacy of @laluprasadrjd 's 15-year rule in Bihar, where our beloved state Bihar plummeted to the rung bottom of economic and social rankings. Law and order crumbled, kidnappings soared, and gangsters turned politicians thrived.

1/ 📊📈 Let's dive into the fascinating world of #statistics and explore two key concepts: Odds Ratio and Relative Risk! Understanding the differences and applications of these two measures is crucial for interpreting study results and making informed decisions. #DataScience

2/ 🎲 Odds Ratio (OR): The Odds Ratio is a measure of association between an exposure and an outcome. It represents the odds of an event occurring in one group compared to the odds in another group. OR is particularly useful in case-control studies. #DataScience
3/ 🌡️ Relative Risk (RR): Also known as Risk Ratio, RR is the ratio of the probability of an event occurring in the exposed group to the probability of the event occurring in the non-exposed group. RR is often used in cohort studies to assess risk. #DataScience
1/ 📊📏 Let's dive into the world of #statistics & explore the Levels of Measurement! Understanding these levels is crucial for choosing the right statistical methods for data analysis. Today, we'll cover the 4 main levels: Nominal, Ordinal, Interval, and Ratio. #DataScience

2/ 🏷️ Nominal Level: At this level, data is purely qualitative and categorical. There's no inherent order or ranking involved. Examples include colors, genders, or nationalities. It's important to note that mathematical operations like addition or subtraction don't apply here.
3/ 🥇🥈🥉 Ordinal Level: This level involves data that has an inherent order or ranking, but the difference between categories is not uniform. Examples include survey responses (Strongly Disagree to Strongly Agree) or educational levels (elementary, high school, college).
🧵1/10: Systematic vs. Random Error 🎯
Welcome to this thread where we'll explore the differences between systematic and random error, two types of error that can impact the accuracy and precision of your data. Let's dive in! #Statistics #DataScience
Welcome to this thread where we'll explore the differences between systematic and random error, two types of error that can impact the accuracy and precision of your data. Let's dive in! #Statistics #DataScience

🧵2/10: Error in Measurements 📏
In any measurement process, there's a possibility of errors occurring. Understanding the types of errors that can arise helps us to design experiments that minimize their impact and improve the quality of our results. #DataScience
In any measurement process, there's a possibility of errors occurring. Understanding the types of errors that can arise helps us to design experiments that minimize their impact and improve the quality of our results. #DataScience
🧵3/10: Systematic Error 📐
Systematic errors, or biases, are consistent and reproducible inaccuracies that occur in the same direction every time. These errors can be due to faulty equipment, incorrect calibration, or even observer bias. #DataScience
Systematic errors, or biases, are consistent and reproducible inaccuracies that occur in the same direction every time. These errors can be due to faulty equipment, incorrect calibration, or even observer bias. #DataScience
🧵1/8 🎲 Ever heard of the Monte Carlo Simulation?
It's a powerful mathematical technique used to model complex systems, make predictions, and optimize decision-making. Let's dive into this fascinating world! #MonteCarloSimulation #Statistics #DataScience
It's a powerful mathematical technique used to model complex systems, make predictions, and optimize decision-making. Let's dive into this fascinating world! #MonteCarloSimulation #Statistics #DataScience
🧵2/8 How does it work? 🤔
Monte Carlo Simulation uses random sampling and statistical models to estimate unknown values. It simulates a system multiple times with different random inputs and aggregates the results to produce predictions. #RandomSampling #DataScience
Monte Carlo Simulation uses random sampling and statistical models to estimate unknown values. It simulates a system multiple times with different random inputs and aggregates the results to produce predictions. #RandomSampling #DataScience
🧵3/8 Applications 💼
From finance to engineering, Monte Carlo Simulation is used across many fields. It helps with risk analysis, portfolio optimization, and even predicting the weather. The versatility of this method is truly remarkable. #DataScience
From finance to engineering, Monte Carlo Simulation is used across many fields. It helps with risk analysis, portfolio optimization, and even predicting the weather. The versatility of this method is truly remarkable. #DataScience
[1/9] 🎲 Let's talk about the difference between probability and likelihood in #statistics. These two terms are often confused, but understanding their distinction is key for making sense of data analysis! #Rstats #DataScience

[2/9]💡Probability is a measure of how likely a specific outcome is in a random process. It quantifies the degree of certainty we have about the occurrence of an event. It ranges from 0 (impossible) to 1 (certain). The sum of probabilities for all possible outcomes is always 1.
[3/9] 📊 Likelihood, on the other hand, is a measure of how probable a particular set of observed data is, given a specific set of parameters for a statistical model. Likelihood is not a probability, but it shares the same mathematical properties (i.e., it's always non-negative).
1/🧵✨Occam's razor is a principle that states that the simplest explanation is often the best one. But did you know that it can also be applied to statistics? Let's dive into how Occam's razor helps us make better decisions in data analysis. #OccamsRazor #Statistics #DataScience
2/ 📏 Occam's razor is based on the idea of "parsimony" - the preference for simpler solutions. In statistics, this means choosing models that are less complex but still accurate in predicting outcomes. #Simplicity #DataScience
3/ 📊 Overfitting is a common problem in statistics, where a model becomes too complex and captures noise rather than the underlying trend. Occam's razor helps us avoid overfitting by prioritizing simpler models with fewer parameters. #Overfitting #ModelSelection #DataScience
🧵1/10 - Law of Large Numbers (LLN) in R 📈
Hello #Rstats community! Today, we're going to explore the Law of Large Numbers (LLN), a fundamental concept in probability theory, and how to demonstrate it using R. Get ready for some code! 🚀
#Probability #Statistics #DataScience
Hello #Rstats community! Today, we're going to explore the Law of Large Numbers (LLN), a fundamental concept in probability theory, and how to demonstrate it using R. Get ready for some code! 🚀
#Probability #Statistics #DataScience
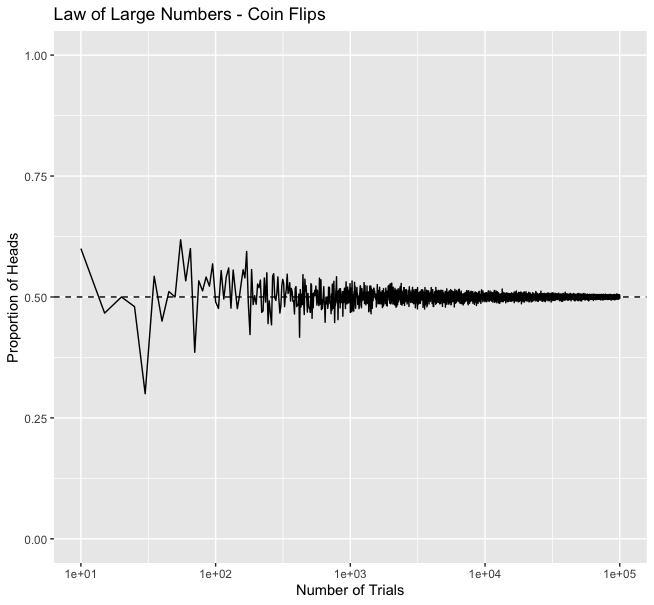
🧵2/10 - What is LLN? 🧐
LLN states that as the number of trials (n) in a random experiment increases, the average of the outcomes converges to the expected value. In other words, the more we repeat an experiment, the closer we get to the true probability.
#RStats #DataScience
LLN states that as the number of trials (n) in a random experiment increases, the average of the outcomes converges to the expected value. In other words, the more we repeat an experiment, the closer we get to the true probability.
#RStats #DataScience
🧵3/10 - Coin Flip Example 🪙
Imagine flipping a fair coin. The probability of getting heads (H) is 0.5. As we increase the number of flips, the proportion of H should approach 0.5. Let's see this in action with R!
#RStats #DataScience
Imagine flipping a fair coin. The probability of getting heads (H) is 0.5. As we increase the number of flips, the proportion of H should approach 0.5. Let's see this in action with R!
#RStats #DataScience
1/🧵 Welcome to this thread on the Central Limit Theorem (CLT), a key concept in statistics! We'll cover what the CLT is, why it's essential, and how to demonstrate it using R. Grab a cup of coffee and let's dive in! ☕️ #statistics #datascience #rstats
2/📚 The Central Limit Theorem states that the distribution of sample means approaches a normal distribution as the sample size (n) increases, given that the population has a finite mean and variance. It's a cornerstone of inferential statistics! #CLT #DataScience #RStats
3/🔑 Why is the CLT important? It allows us to make inferences about population parameters using sample data. Since many statistical tests assume normality, CLT gives us the foundation to apply those tests even when the underlying population is not normally distributed. #RStats
1/10: 🧵 Welcome to this thread on #regression modeling strategies in #R! We'll discuss key techniques and packages to help you build effective models. Ready to dive in? Let's go! 🚀 #RStats #DataScience #Statistics

2/10: 🌐 Linear Regression: Start with simple & multiple linear regression using 'lm()' function. Check out the 'broom' package for easy-to-use regression output! #RStats cran.r-project.org/web/packages/b…
3/10:🏞️ Polynomial Regression: When data is nonlinear, try polynomial regression! Use 'poly()' to create higher-order terms. Beware of overfitting! #RStats

Roadmap to becoming Data Analyst in three months absolutely free. No need to pay a penny for this.
I have mentioned a roadmap with free resources.
A thread🧵👇
I have mentioned a roadmap with free resources.
A thread🧵👇

1. First Month Foundations of Data Analysis
A. Corey Schafer - Python Tutorials for Beginners:
B. StatQuest with Josh Starmer - Statistics Fundamentals:
C. Ken Jee - Data Analysis with Python
A. Corey Schafer - Python Tutorials for Beginners:
B. StatQuest with Josh Starmer - Statistics Fundamentals:
C. Ken Jee - Data Analysis with Python
2. Second Month - Advanced Data Analysis Techniques
A. Sentdex - Machine Learning with Python
B. StatQuest with Josh Starmer - Machine Learning Fundamentals
C. Brandon Foltz - Business Analytics
A. Sentdex - Machine Learning with Python
B. StatQuest with Josh Starmer - Machine Learning Fundamentals
C. Brandon Foltz - Business Analytics
Python project ideas for beginners with source code
A thread 🧵👇
A thread 🧵👇



Python for data science beginners roadmap
A thread 🧵👇
A thread 🧵👇

1. Python Basics
Codecademy's Python Course (codecademy.com/learn/learn-py…)
Python for Everybody Course (py4e.com)
Codecademy's Python Course (codecademy.com/learn/learn-py…)
Python for Everybody Course (py4e.com)
2. Data Analysis Libraries
NumPy User Guide (numpy.org/doc/stable/use…)
Pandas User Guide (pandas.pydata.org/docs/user_guid…)
Matplotlib Tutorials (matplotlib.org/stable/tutoria…)
NumPy User Guide (numpy.org/doc/stable/use…)
Pandas User Guide (pandas.pydata.org/docs/user_guid…)
Matplotlib Tutorials (matplotlib.org/stable/tutoria…)


Top 25 SQL Interview Questions and Answers
🧵
🧵
There are certain SQL concepts which you should be familiar with if you plan to attend an #SQL interview. No matter which RDBMS you use wether it is MySQL, Oracle, Microsoft SQL Server, #PostgreSQL or any other, these SQL concepts are common for all of the popular RDBMS.

THE FOLLOWING IS QUOTED FROM BERGAN EVANS
ON NORBERT #WEINER, NUCLEAR PHYSICIST !!!
The #second concept Wiener has to establish is that of entropy. Probability is a #mathematical concept, coming from #statistics.
ON NORBERT #WEINER, NUCLEAR PHYSICIST !!!
The #second concept Wiener has to establish is that of entropy. Probability is a #mathematical concept, coming from #statistics.

Entropy comes from physics. It is the assertion-- established logically and experimentally-- that the universe, by its nature, is "running down", moving toward a state of inert uniformity devoid of form, matter, hierarchy or differentiation.....

That is, in any given situation, less organization, more #chaos, is overwhelmingly more probable than tighter #organization or more order.
Clear Consequences [Y]
Apparent Order
Apparent Disorder
Clear Consequences [Y]
Apparent Order
Apparent Disorder


💥14 herramientas secretas impulsadas por #RStats para ahorrar tiempo y esfuerzo en tus proyectos de datos (¡No te lo pierdas!):👀
1️⃣ ¡Edita tus datos de forma interactiva (y guarda el código)! 👀
📦 'editData' es un complemento de RStudio para editar un data.frame o un tibble de forma interactiva
🔗 buff.ly/3U5Tgjy
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
📦 'editData' es un complemento de RStudio para editar un data.frame o un tibble de forma interactiva
🔗 buff.ly/3U5Tgjy
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
2️⃣ ¡Crea gráficos #ggplot de forma interactiva!🚀
📦esquisse es otro de mis addins favoritos de #rstudio
✅ exporta el gráfico o recupera el código para reproducir el gráfico
🔗 buff.ly/3mxLHSo
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics
📦esquisse es otro de mis addins favoritos de #rstudio
✅ exporta el gráfico o recupera el código para reproducir el gráfico
🔗 buff.ly/3mxLHSo
#DataScience #DataVisualization #dataviz #stats #analytics #RStats #Analytics

Machine Learning is hard.
I felt like quitting whenever I get baffled by the amount of information to learn.
But I followed the path to learning from Math for ML.
Here are the 5 critical reasons why you should start with Math concepts for ML
THREAD🧵 ↓
I felt like quitting whenever I get baffled by the amount of information to learn.
But I followed the path to learning from Math for ML.
Here are the 5 critical reasons why you should start with Math concepts for ML
THREAD🧵 ↓
🤔 Why Math for ML:
**********************
📌 Machine learning algorithms rely on mathematical calculations to make predictions and decisions
**********************
📌 Machine learning algorithms rely on mathematical calculations to make predictions and decisions
📌 Many machine learning techniques, such as neural networks and deep learning, are based on linear algebra and calculus

Learn SQL projects for Data Analysis and add to your portfolio for free 🥳
Projects for the portfolio are very important. These projects will improve your skills
A thread 🧵👇
Projects for the portfolio are very important. These projects will improve your skills
A thread 🧵👇

1.
2.

🧬🧵here is a Twitter thread explaining #Bioinformatics in simple terms:🧬🧵
#Bioinformatics is the field that uses computational tools and methods to analyze and interpret #biological #data.
This can include analyzing #DNA and #protein #sequences, predicting the structure and function of #molecules, and modeling biological systems.

Is the #Bitcoin price a stationary times series? 🤔
Check 👇 how to find it out!
#DataScience #MachineLearning
Check 👇 how to find it out!
#DataScience #MachineLearning
We know that stationary means that the mean and variance of the time series data do not vary across time.
To be sure of that we can perform the Augmented Dickey-Fuller test.
To be sure of that we can perform the Augmented Dickey-Fuller test.
If you are familiar with #statistics here you have the hypotheses for this test:
H0️⃣ (Null hypothesis) = Time series non-stationary
H1️⃣ (Alternative hypothesis) = Time series is stationary
After the test, we will pay attention to the "p-value".
H0️⃣ (Null hypothesis) = Time series non-stationary
H1️⃣ (Alternative hypothesis) = Time series is stationary
After the test, we will pay attention to the "p-value".

A translation of my first thread for the general public out there. I will talk about how to correctly, yet efficiently model the uncertainty on predictions (for example in machine learning). (1/n)
#statistics #DataScience #machinelearning #conformalprediction
#statistics #DataScience #machinelearning #conformalprediction
When I started as a PhD I was convinced of two things:
1) Modelling uncertainty is hard, and
2) The only viable approach is the Bayesian one.
This idea is so strongly ingrained in the statistical literature and data science community that it must be true, right? (2/n)
1) Modelling uncertainty is hard, and
2) The only viable approach is the Bayesian one.
This idea is so strongly ingrained in the statistical literature and data science community that it must be true, right? (2/n)
The answer is no and luckily I quickly learned of a great alternative. The idea behind "Conformal prediction" is as simple as possible: You calculate the errors on a holdout dataset and choose, for example, the 90% quantile. (3/n)
Mijn eerste draadje (zoals men dit blijkbaar noemt) gaat over het correct, maar eenvoudig modelleren van de onzekerheid op voorspellingen. (1/n)
#Statistics #DataScience #machinelearning #conformalprediction
#Statistics #DataScience #machinelearning #conformalprediction
Toen ik begon als PhD was ik van twee dingen overtuigd:
1) Onzekerheid op voorspellingen modelleren is niet eenvoudig.
2) Dit kan enkel op een Bayesiaanse manier.
Dit idee is zo sterk verspreid binnen de statistiek en datawetenschappen dat het wel waar moet zijn. Of niet? (2/n)
1) Onzekerheid op voorspellingen modelleren is niet eenvoudig.
2) Dit kan enkel op een Bayesiaanse manier.
Dit idee is zo sterk verspreid binnen de statistiek en datawetenschappen dat het wel waar moet zijn. Of niet? (2/n)
Gelukkig leerde ik al vrij snel een alternatief kennen. Het idee achter "Conformal prediction" is zo simpel als het maar kan zijn: je berekent de fouten op wat validatiedata en kiest bijvoorbeeld het 90%-kwantiel. (3/n)

Fit a polynomial of degree D to N points by minimising the mean squared error. Now, start increasing D and look at the accuracy. The accuracy blows-up around D~N and starts improving *again* for D>>N 🙂
#doubleDescent #statistics #maths
#doubleDescent #statistics #maths

