Day 12: #100DaysofCode
Built a handwritten digit recognition algorithm using neural networks. Trained it. Tested it. Understanding the concepts - a thread.
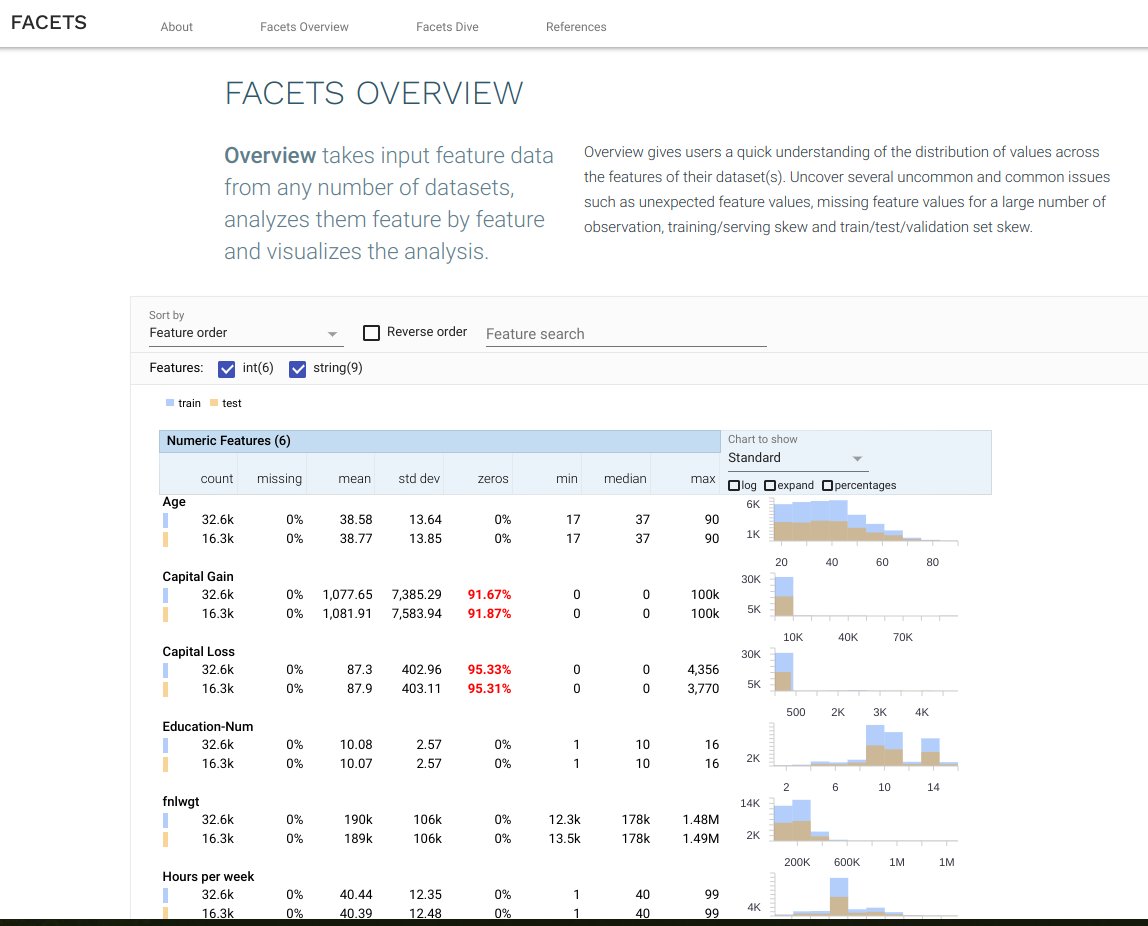
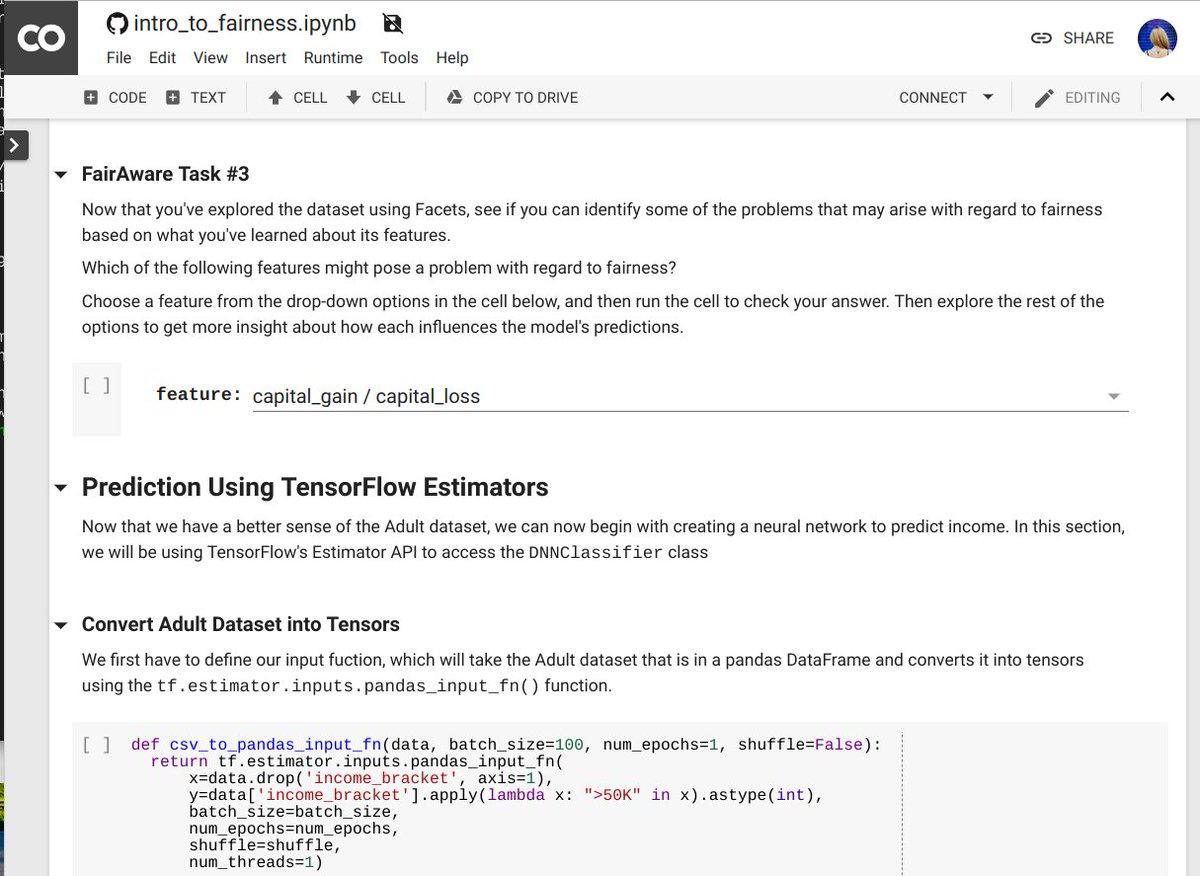
colab.research.google.com/drive/1-neDSoL…
#100DaysOfMLCode @myorwah @esemejeomole
Built a handwritten digit recognition algorithm using neural networks. Trained it. Tested it. Understanding the concepts - a thread.
colab.research.google.com/drive/1-neDSoL…
#100DaysOfMLCode @myorwah @esemejeomole
A neural network consists of a input layer, hidden layer (middle layer) and the output layer. The input layer takes in the input (images, files, audio, video etc), passes it to the hidden layer where come processing/learning is done and passed to the output layer for results.
Take a moment to think about this: let's assume you are in a group of 3 friends and you want to tell your 3rd friend you love her. You are the first friend, your second friend, Jay is the middleman or the channel of communication between you and your 3rd friend, Lola.
It means you are the input node(s), Jay is the hidden/middle node and Lola is the output node. Let's say you made a casual whisper to Jay to inform Lola you love her. Jay is reluctant but goes on to say it to Lola.
Its easy for Lola to smile and discard it - meaning the output was not strong enough. Let's assume you call Jay to a corner and tell him with all seriousness that you love Lola and that he should tell Lola the same say you told him.
Jay did exactly what you told him. Lola would likely take it more seriously put that into consideration. She might even reply telling you she loves you too. The words you said are the input, the whispered joking word can be said to have a small weight - its not really serious.
While the seriousness you added to the corner talk had more weight in shaping Lola's response. This is explains the basics of how neural network works. Its takes the product of the input from each layer multiplies it by the weight to give an output.
Now, let's assume Jay told Lola that you "like" her instead of "love". That's an error. You had it mind that he would tell Lola with all seriousness that you love her but he didn't. What you had in mind was an intended output (target) while what Jay said was the actual output.
Mathematically we can calculate this as:
output error = intended output - actual output.
output error = intended output - actual output.
We can moderate this output error by including a learning rate. This learning rate is a figure that we'd multiply with the output error to reduce it so that when next we tell Jay to speak with Lola, the error is minimized. The learning rate is usually a small number.
Before we wrap up, lets assume that Lola has a level or threshold that must be met before she takes people's word into consideration. I mean, there's a level of 'trust' that must met for her to "believe" the speaker.
Mathematically, the threshold that measures the level of 'trust' is called the activation/sigmoid/logistic function.
So it means, Jay must meet that level for her to believe him.
So it means, Jay must meet that level for her to believe him.
Trust me, we all have it. So it means even for you & Jay, there's also a level of seriousness or trust that must be overcome before you can pass your message across.
Putting this analogy to the neural network, all layers (input, hidden & output layers) have an activation function that must be overcome for a successful message transfer.
Finally, you can improve the output by increasing the number of times you relay your message to Jay as he also speaks to Lola. If you notice that Lola's output was way below our intended result, you can call Jay to the corner again to tell him the same message to tell.
Hoping that it would minimize Jay's error and improve Lola's output.
The number of times we relay our message (input) is called an epoch. We can have 5 epochs so as to improve our output. And the process of relaying the message is called training.
The number of times we relay our message (input) is called an epoch. We can have 5 epochs so as to improve our output. And the process of relaying the message is called training.
Now lets make a recap:
Input layer: is the entrance of the neural network
Hidden layer: where communication (learning) happens
Output layer: where the results happen
Output error: intended output - actual error
Learning rate: moderating factor used to minimize the error
Input layer: is the entrance of the neural network
Hidden layer: where communication (learning) happens
Output layer: where the results happen
Output error: intended output - actual error
Learning rate: moderating factor used to minimize the error
Activation function: threshold that must be overcome for an input to move to the next layer. It takes in the input at every layer.
Epoch: number of times a training is carried out.
Epoch: number of times a training is carried out.
Putting it all together, a neural network combines the inputs, learning rate, weights, errors and the activation function to give us the output.
Codes: colab.research.google.com/drive/1-neDSoL… cc @sirajraval @BecomingDataSci #SoDS
All credit goes to @rzeta0 for his book: tinyurl.com/yczslhpz
Codes: colab.research.google.com/drive/1-neDSoL… cc @sirajraval @BecomingDataSci #SoDS
All credit goes to @rzeta0 for his book: tinyurl.com/yczslhpz
please unroll @threadreaderapp