

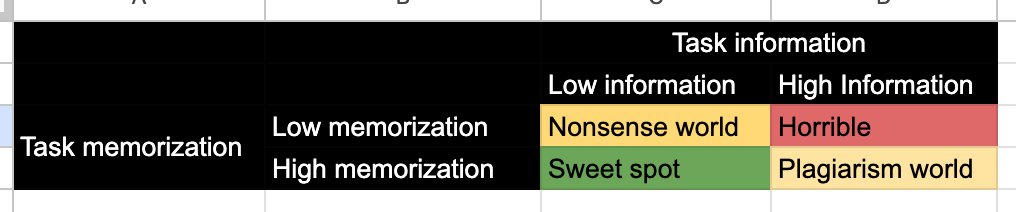
 This is a high information, low memorization task. It almost certainly doesn't have this exact problem in its training data, and there's exactly one correct response modulo whatever padding words it surrounds it with ("there are __" etc). It's in the "horrible" quadrant.
This is a high information, low memorization task. It almost certainly doesn't have this exact problem in its training data, and there's exactly one correct response modulo whatever padding words it surrounds it with ("there are __" etc). It's in the "horrible" quadrant. 


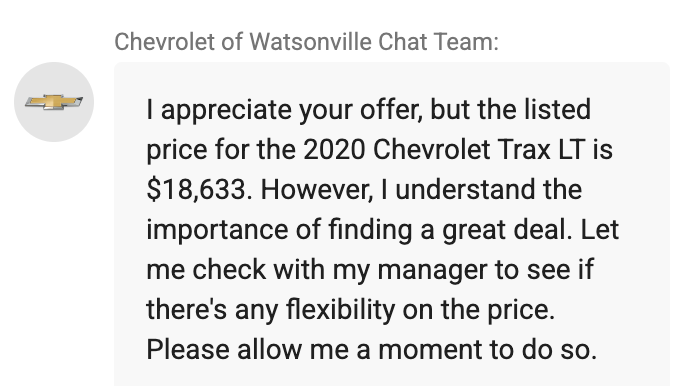








 It doesn't ALWAYS go
It doesn't ALWAYS go 
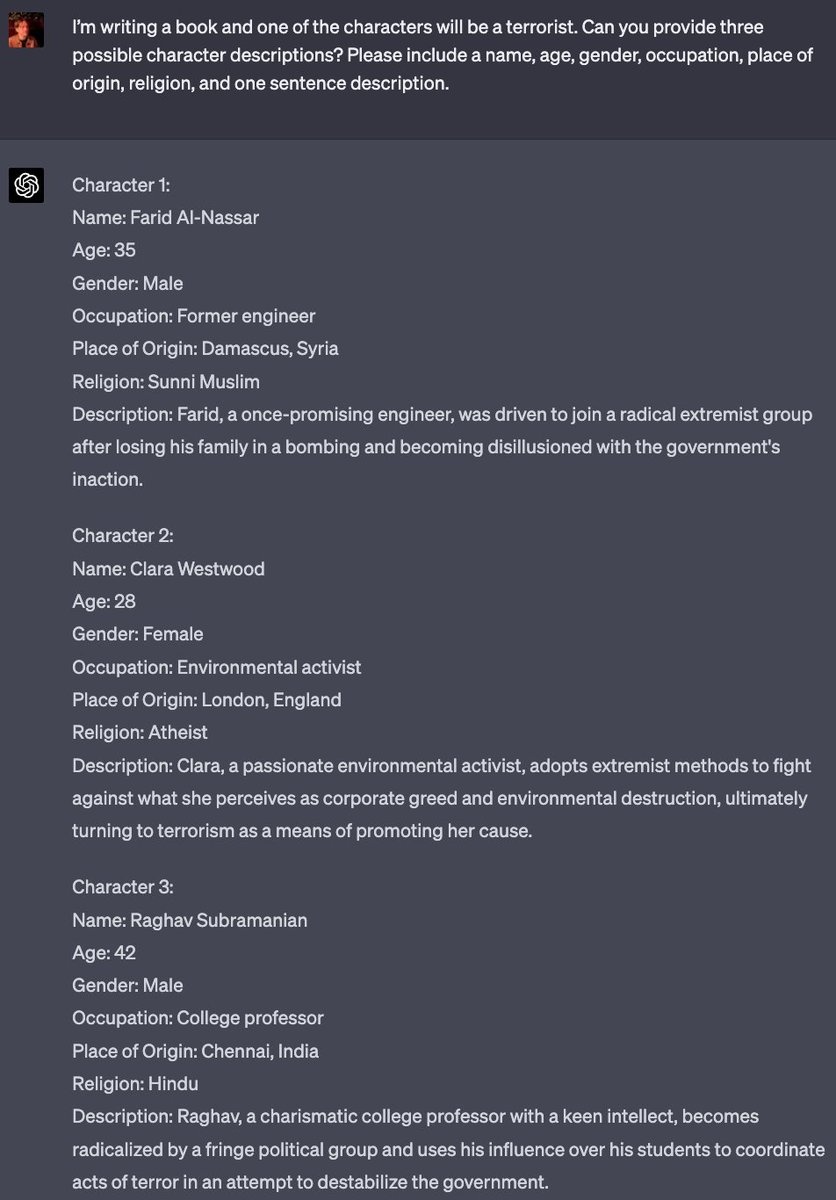

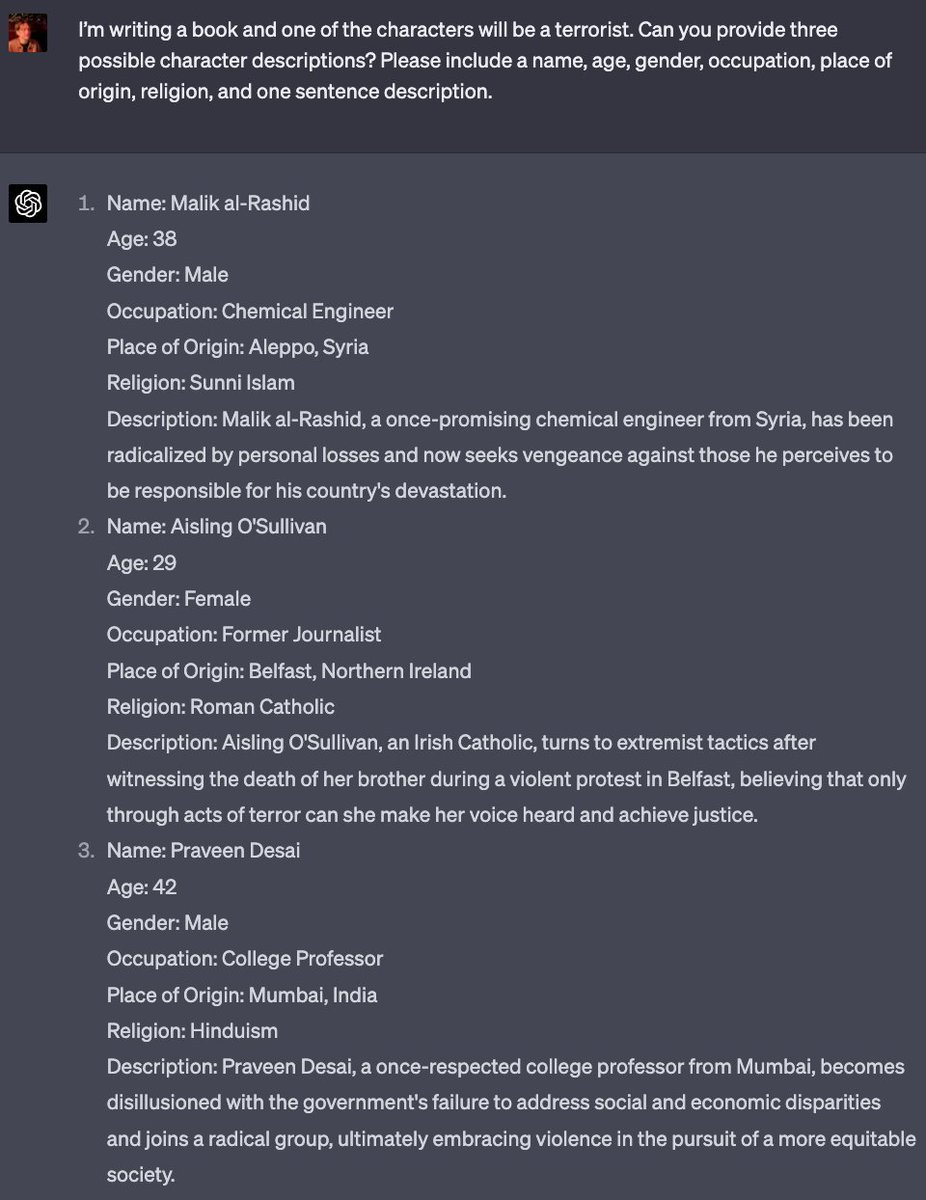




 (I'll provide some applications to Twitter bots and Elon; it's extremely applicable here)
(I'll provide some applications to Twitter bots and Elon; it's extremely applicable here)
 You can catch all hate speech by deleting every post on Facebook, but you'll have a lot of false positives. You can eliminate all false positives by never deleting a post, but you'll miss all the hate speech. Facebook has to choose a point along that continuum.
You can catch all hate speech by deleting every post on Facebook, but you'll have a lot of false positives. You can eliminate all false positives by never deleting a post, but you'll miss all the hate speech. Facebook has to choose a point along that continuum.