Discover and read the best of Twitter Threads about #DataEngineering
Most recents (24)

Troubleshooting slow Spark jobs is a special type of data engineering torture!
What are the common culprits? 1/5
What are the common culprits? 1/5
- Inadequate initial file parallelism If your upstream data tables are written to too few files, you can't increase the parallelism much unless you work with the upstream pipeline to write more files. This can increase the speed of your job dramatically! 2/5
- Not enough memory/disk spillage
Disk spillage happens when Spark needs more RAM to process the data and uses ROM instead. Disk spillage hurts perf! You can solve bumping up executor memory or increasing parallelism. This can also be caused by skew 3/5
Disk spillage happens when Spark needs more RAM to process the data and uses ROM instead. Disk spillage hurts perf! You can solve bumping up executor memory or increasing parallelism. This can also be caused by skew 3/5

Testing your pipelines before merging is crucial to ensure they do not fail in production. However, testing data pipelines is complex (and expensive) due to the data size, confidentiality, and time it takes to test a data pipeline.
🧵
#data #dataengineering #testing #dataops
🧵
#data #dataengineering #testing #dataops
Here are a few ways to get data for your tests:
1. Copying data: An exact copy of the prod data for testing will ensure that our changes are not breaking the pipeline. This is expensive! You can use a part of data for testing, accepting possible edge case misses.
1. Copying data: An exact copy of the prod data for testing will ensure that our changes are not breaking the pipeline. This is expensive! You can use a part of data for testing, accepting possible edge case misses.
2. Data git: Projects like Nessie and LakeFS can help set up different environments without replicating entire data.
Data engineers work with multiple systems & it's crucial to understand DevOps. Shown below are a few DevOps concepts to familiarize oneself with:
1. Docker: docs.docker.com/get-started/
2. Kubernetes: kubernetes.io/docs/concepts/…
3. CI/CD: resources.github.com/ci-cd/
#dataengineering
#data
1. Docker: docs.docker.com/get-started/
2. Kubernetes: kubernetes.io/docs/concepts/…
3. CI/CD: resources.github.com/ci-cd/
#dataengineering
#data
4. IAC: pulumi.com/what-is/what-i…
5. Monitoring: atlassian.com/devops/devops-…
6. Access control: techtarget.com/searchsecurity…
7. Key management: aws.amazon.com/kms/?c=sc&sec=…
8. Encrypted connections: dev.mysql.com/doc/refman/8.0…
5. Monitoring: atlassian.com/devops/devops-…
6. Access control: techtarget.com/searchsecurity…
7. Key management: aws.amazon.com/kms/?c=sc&sec=…
8. Encrypted connections: dev.mysql.com/doc/refman/8.0…
That's a wrap!
If you enjoyed this thread:
1. Follow me @startdataeng for more of these
2. RT the tweet below to share this thread with your audience
If you enjoyed this thread:
1. Follow me @startdataeng for more of these
2. RT the tweet below to share this thread with your audience
Things I’ve learned running my data engineering boot camp for 2 weeks!
- don’t use platforms like Maven which take 10%. Google classroom is free and good enough. 1/5
- don’t use platforms like Maven which take 10%. Google classroom is free and good enough. 1/5
- be more than 1 day ahead of the boot camp. When curricula building you should be working on the next weeks curricula this week so your students can review the materials before.
- use Postgres 14+ on your SQL sections otherwise you don’t have access to BIT_COUNT function 2/5
- use Postgres 14+ on your SQL sections otherwise you don’t have access to BIT_COUNT function 2/5
- use 1 long-standing Zoom call instead of 1 Zoom call per session. This makes it easier for students to know where to go and don’t use the Google Calendar + Zoom integration, it’s really bad!
- give people more time on the homework. Strict deadlines are for college not boot… twitter.com/i/web/status/1…
- give people more time on the homework. Strict deadlines are for college not boot… twitter.com/i/web/status/1…
How to use ChatGPT to speed up data pipeline dev in a few easy steps:
1. Supply ChatGPT with your input schemas. Paste your CREATE TABLE statements directly. ChatGPT knows how to parse these and make sense of the fields inside
1/4
1. Supply ChatGPT with your input schemas. Paste your CREATE TABLE statements directly. ChatGPT knows how to parse these and make sense of the fields inside
1/4
2. Specify what type of analytical pattern you want to do on this data. ChatGPT understands aggregation (for GROUP BY queries), cumulation (for FULL OUTER JOIN queries), enrichment (for JOIN queries) and slowly changing dimension patterns.
2/4
2/4
3. ChatGPT needs more context on WHICH fields it should apply these patterns to. If you don’t supply that, it’ll give you flaming garbage.
Example: “apply slowly changing dimension type 2 pattern to fields age, gender, and phone os”
3/4
Example: “apply slowly changing dimension type 2 pattern to fields age, gender, and phone os”
3/4
My data eng boot camp curricula has been updated:
- Week 1: Dimension Data Modeling
Day 1: understanding dimensions. Daily dimensions vs SCDs. How to pick SCD type 1/2/3
Day 2: applied dimension data modeling. backfilling SCD tables. Incremental building SCD tables.
1/8
- Week 1: Dimension Data Modeling
Day 1: understanding dimensions. Daily dimensions vs SCDs. How to pick SCD type 1/2/3
Day 2: applied dimension data modeling. backfilling SCD tables. Incremental building SCD tables.
1/8
- Week 2: Fact Data Modeling
Day 1: understand facts. denormalized facts vs normalized facts. How to collaborate and get logging right.
Day 2: applied fact data modeling. Reduced facts for efficient long-term analysis. Cumulative table design for efficient fact analysis. 2/8
Day 1: understand facts. denormalized facts vs normalized facts. How to collaborate and get logging right.
Day 2: applied fact data modeling. Reduced facts for efficient long-term analysis. Cumulative table design for efficient fact analysis. 2/8
- Week 3: Spark
Day 1: understanding when to use Spark. Deep dive into Spark architecture and bottlenecks
Day 2: applied Spark.
understand the parallelism vs network overhead. SparkSQL vs DataFrame vs Dataset.
I’ll lead Scala Spark and @ADutchEngineer will lead PySpark
3/8
Day 1: understanding when to use Spark. Deep dive into Spark architecture and bottlenecks
Day 2: applied Spark.
understand the parallelism vs network overhead. SparkSQL vs DataFrame vs Dataset.
I’ll lead Scala Spark and @ADutchEngineer will lead PySpark
3/8

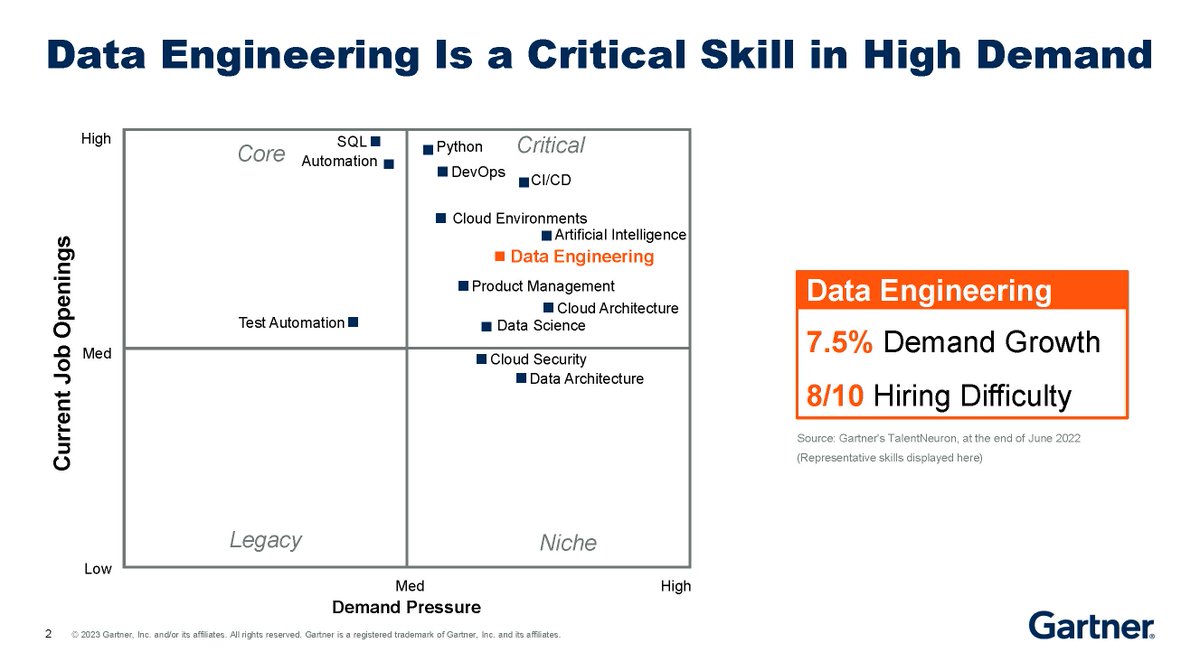
Live from #GartnerDA | 5 Ways to Enhance Your Data Engineering Practices with Robert Thanaraj, Gartner Director Analyst: gtnr.it/3JOkYPF 

About this session: Analytics relies on a successful data foundation; it must be backed with the right data and processes. Robert explores 5 ways to enhance your #DataEngineering practices: gtnr.it/3JOkYPF #GartnerDA
#DataEngineering is a critical skill in high demand amongst employers with a 7.5% increase in demand. #GartnerDA

" SQL Puzzle Interview Question "
🧵
🧵
Table script:
create table input (
id int,
formula varchar(10),
value int
)
insert into input values (1,'1+4',10),(2,'2+1',5),(3,'3-2',40),(4,'4-1',20);
create table input (
id int,
formula varchar(10),
value int
)
insert into input values (1,'1+4',10),(2,'2+1',5),(3,'3-2',40),(4,'4-1',20);
" Exploratory Data Analysis on Terrorism "
🧵
🧵
We are performed Exploratory Data Analysis on terrorism #dataset to find out the hot zone of #terrorism. #EDA nothing but #analyzing the given data & finding the #trends, patterns & making some assumptions. #DataVisualization #DataScience #MachineLearning
In this #dataset, there are many features including countries, states, regions, gang names, weapon types, target types, years, months, days, and many more features.

What is a correct Data Engineering Learning Path?
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

I believe that the following is a correct order to start in 𝗬𝗼𝘂𝗿 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗮𝘁𝗵:
👇
👇
➡️ 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝗕𝗮𝘀𝗶𝗰 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗲𝘀:
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
What are the basics of Writing Data to a Kafka Topic?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
➡️ Clients writing to Kafka are called 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀,
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
Quick guide to go from 0 to #dataengineering hero:
- learn SQL
Data Lemur is a great resource here
- learn Python
Do like… 30-40 leetcode easy and medium questions
- distributed compute
Get a trial of Databricks or Snowflake and find a training to learn about it
1/3
- learn SQL
Data Lemur is a great resource here
- learn Python
Do like… 30-40 leetcode easy and medium questions
- distributed compute
Get a trial of Databricks or Snowflake and find a training to learn about it
1/3
- data modeling
Find a dimension table like users that you can snapshot daily. Learn about slowly changing dimensions.
Find a fact/event table that you can aggregate and learn about fact modeling
- job orchestration
Learn Mage or Airflow to do your daily automated tasks
2/3
Find a dimension table like users that you can snapshot daily. Learn about slowly changing dimensions.
Find a fact/event table that you can aggregate and learn about fact modeling
- job orchestration
Learn Mage or Airflow to do your daily automated tasks
2/3
- data story telling
Take a training by Tableau on data visualization and how to tell stories with data
- communication
Read crucial conversations and radical candor books. They’ll help a lot!
If you just do this, you’ll be a lot closer to a great data engineering job! 3/3
Take a training by Tableau on data visualization and how to tell stories with data
- communication
Read crucial conversations and radical candor books. They’ll help a lot!
If you just do this, you’ll be a lot closer to a great data engineering job! 3/3
So what is the difference between Row Based and Column Based file formats?
🧵
#Data #DataEngineering #MLOps #MachineLearning
🧵
#Data #DataEngineering #MLOps #MachineLearning
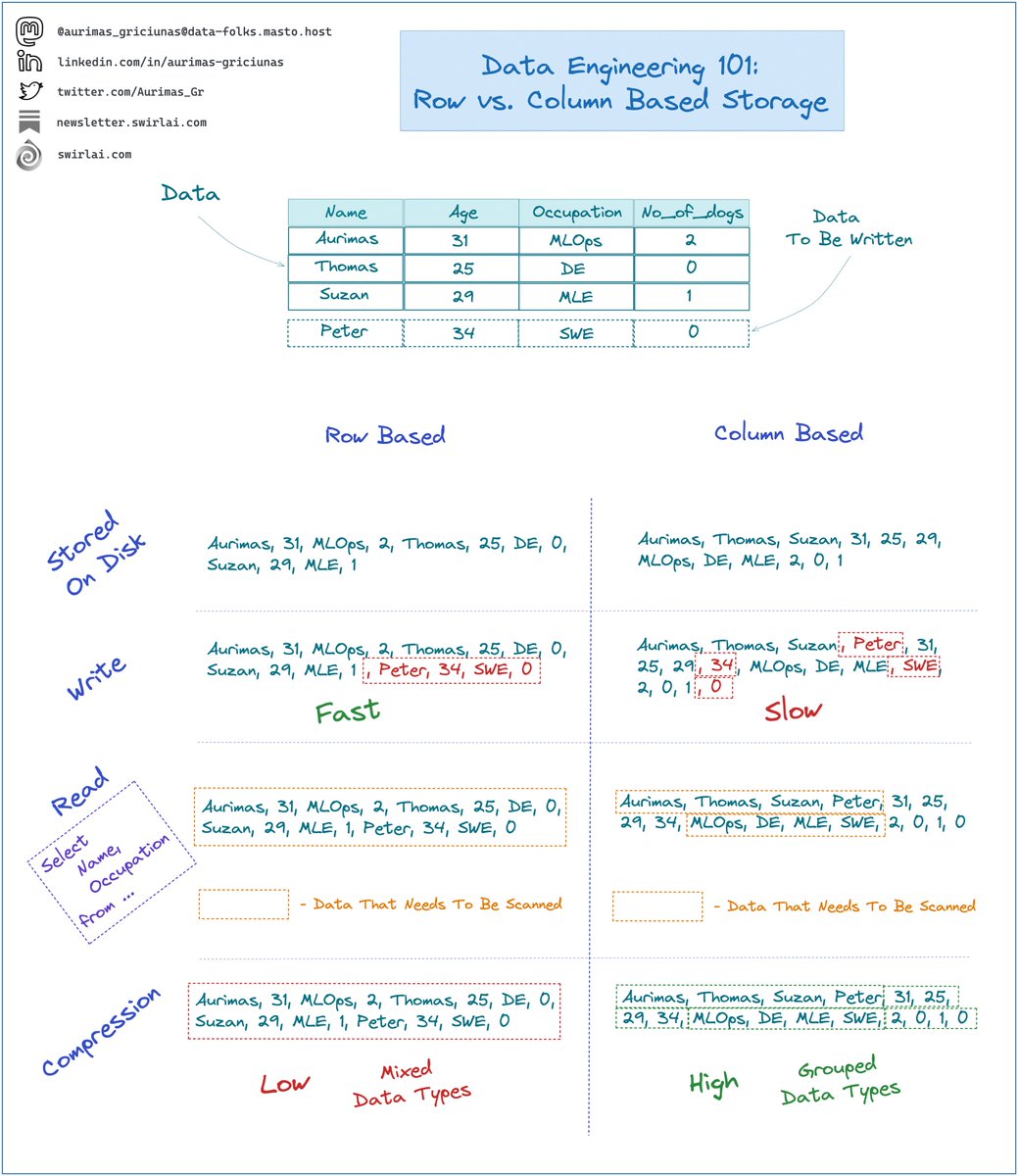
𝗥𝗼𝘄 𝗕𝗮𝘀𝗲𝗱:
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ For select statements that target a subset of columns, reading is slower since you need to scan all sets of rows to retrieve one of the columns.
👇
👇
What are the main use cases for Apache Kafka or any other Distributed Messaging System?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer?
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗪𝗲𝗯𝘀𝗶𝘁𝗲 𝗔𝗰𝘁𝗶𝘃𝗶𝘁𝘆 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴.
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇

Roadmap to becoming Data Analyst in three months absolutely free. No need to pay a penny for this.
I have mentioned a roadmap with free resources.
A thread🧵👇
I have mentioned a roadmap with free resources.
A thread🧵👇

1. First Month Foundations of Data Analysis
A. Corey Schafer - Python Tutorials for Beginners:
B. StatQuest with Josh Starmer - Statistics Fundamentals:
C. Ken Jee - Data Analysis with Python
A. Corey Schafer - Python Tutorials for Beginners:
B. StatQuest with Josh Starmer - Statistics Fundamentals:
C. Ken Jee - Data Analysis with Python
2. Second Month - Advanced Data Analysis Techniques
A. Sentdex - Machine Learning with Python
B. StatQuest with Josh Starmer - Machine Learning Fundamentals
C. Brandon Foltz - Business Analytics
A. Sentdex - Machine Learning with Python
B. StatQuest with Josh Starmer - Machine Learning Fundamentals
C. Brandon Foltz - Business Analytics
Python project ideas for beginners with source code
A thread 🧵👇
A thread 🧵👇



Python for data science beginners roadmap
A thread 🧵👇
A thread 🧵👇

1. Python Basics
Codecademy's Python Course (codecademy.com/learn/learn-py…)
Python for Everybody Course (py4e.com)
Codecademy's Python Course (codecademy.com/learn/learn-py…)
Python for Everybody Course (py4e.com)
2. Data Analysis Libraries
NumPy User Guide (numpy.org/doc/stable/use…)
Pandas User Guide (pandas.pydata.org/docs/user_guid…)
Matplotlib Tutorials (matplotlib.org/stable/tutoria…)
NumPy User Guide (numpy.org/doc/stable/use…)
Pandas User Guide (pandas.pydata.org/docs/user_guid…)
Matplotlib Tutorials (matplotlib.org/stable/tutoria…)

How should you 𝐥𝐞𝐚𝐫𝐧 𝐏𝐨𝐰𝐞𝐫 𝐁𝐈? 🚀
🧵
🧵
It's easy to be overwhelmed by how broad #PowerBI is😖
If you're starting out, here's the path I recommend⏬
If you're starting out, here's the path I recommend⏬
📊 𝐃𝐚𝐭𝐚 𝐌𝐨𝐝𝐞𝐥𝐢𝐧𝐠
Begin by learning to organize data into tables, create relationships, and add calculated columns and measures.
This is the most important part of your journey, as understanding the #data is always the first step in Power BI development.
Begin by learning to organize data into tables, create relationships, and add calculated columns and measures.
This is the most important part of your journey, as understanding the #data is always the first step in Power BI development.
▶️Practice Writing SQL Queries using Real
Dataset 💯
🧵
Dataset 💯
🧵
“The very first thing, we must do when writing #SQL queries, is to understand the underlying data. Once we understand the data and how this data is stored across different tables, it becomes much simpler to write SQL #Queries to retrieve any information from that data”
✅List of SQL Queries:
We shall write SQL #Queries using this data. For each of these queries, you would find the problem statement and then the screen shot of the expected output. Under each of these 20 problem statement
We shall write SQL #Queries using this data. For each of these queries, you would find the problem statement and then the screen shot of the expected output. Under each of these 20 problem statement
Considering switching to a 𝗠𝗟𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 role?
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Usually MLOps Engineers are professionals tasked with building out the ML Platform in the organization.
👇
👇
This means that the skill set required is very broad - naturally very few people start off with the full set of skills you would need to brand yourself as a MLOps Engineer. This is why I would not choose this role if you are just entering the market.
👇
👇
What is the difference between Splittable and Non-Splittable Files?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

You are very likely to run into a 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗼𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 in your career. It could be 𝗦𝗽𝗮𝗿𝗸, 𝗛𝗶𝘃𝗲, 𝗣𝗿𝗲𝘀𝘁𝗼 or any other.
👇
👇
Also, it is very likely that these Frameworks would be reading data from a distributed storage. It could be 𝗛𝗗𝗙𝗦, 𝗦𝟯 etc.
👇
👇
So how do we implement 𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗚𝗿𝗮𝗱𝗲 𝗕𝗮𝘁𝗰𝗵 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 in 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
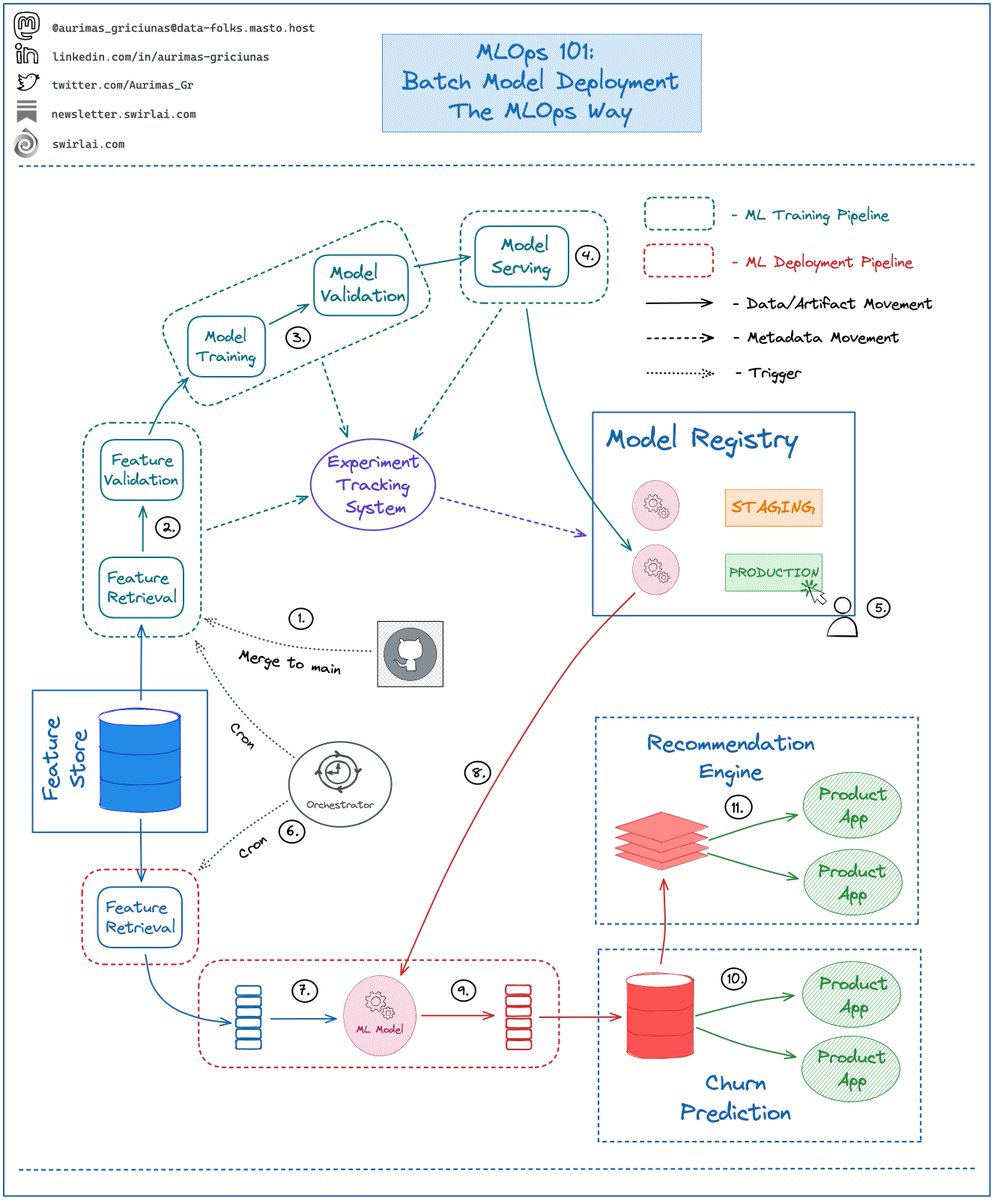
Let’s zoom in:
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟮: Feature preprocessing stage: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata is saved to an Experiment Tracking System.
👇
👇
How do we 𝗗𝗲𝗰𝗼𝗺𝗽𝗼𝘀𝗲 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝗲𝗿𝘃𝗶𝗰𝗲 𝗟𝗮𝘁𝗲𝗻𝗰𝘆 and why should you care to understand the pieces as a ML Engineer?
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Usually, what is cared about by the users of your Machine Learning Service is the total endpoint latency - the time difference between when a request is performed (1.) against the Service till when the response is received (6.).
👇
👇
Certain SLAs will be established on what the acceptable latency is and you will need to reach that. Being able to decompose the total latency is even more important as you can improve each piece independently. Let's see how.
👇
👇

El ecosistema de ingeniería de datos evoluciona a altísima velocidad. Ya es tiempo de que subas de level y conozcas más allá de numpy, pandas y matplotlib.
🐍Abro hilo pythónico
🧵[1/x]
#python #dataengineering
🐍Abro hilo pythónico
🧵[1/x]
#python #dataengineering
Redpanda 🐼 : redpanda.com
Redpanda ofrece un performance superior a Apache Kafka y manteniendo la compatibilidad con el API.
¿Será tan poderoso como Google PubSub?
🧵[2/x]
#python #dataengineering
Redpanda ofrece un performance superior a Apache Kafka y manteniendo la compatibilidad con el API.
¿Será tan poderoso como Google PubSub?
🧵[2/x]
#python #dataengineering
DuckDB 🦆 : duckdb.org
DuckDB nos permite hacer OLAP desde nuestro navegador web y tener un motor que funciona bastante bien con Parquet. MotherDuck motherduck.com está buscando ofrecer como Saas DuckDB a gran escala.
🧵[3/x]
#python #dataengineering
DuckDB nos permite hacer OLAP desde nuestro navegador web y tener un motor que funciona bastante bien con Parquet. MotherDuck motherduck.com está buscando ofrecer como Saas DuckDB a gran escala.
🧵[3/x]
#python #dataengineering
