Discover and read the best of Twitter Threads about #MLOps
Most recents (24)

What is a correct Data Engineering Learning Path?
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thoughts in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

I believe that the following is a correct order to start in 𝗬𝗼𝘂𝗿 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗮𝘁𝗵:
👇
👇
➡️ 𝗨𝗻𝗱𝗲𝗿𝘀𝘁𝗮𝗻𝗱 𝗕𝗮𝘀𝗶𝗰 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗲𝘀:
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
👉 Data Extraction
👉 Data Validation
👉 Data Contracts
👉 Loading Data into a DWH / Data Lake
👉 Transformations in a DWH / Data Lake
👉 Scheduling
👇
What are the basics of Writing Data to a Kafka Topic?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Kafka is an extremely important 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 to understand as it was the first of its kind and most of the new products are built on the ideas of Kafka.
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
𝗦𝗼𝗺𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝗹 𝗱𝗲𝗳𝗶𝗻𝗶𝘁𝗶𝗼𝗻𝘀:
👇
➡️ Clients writing to Kafka are called 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀,
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
➡️ Clients reading the Data are called 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀.
➡️ Data is written into 𝗧𝗼𝗽𝗶𝗰𝘀 that can be compared to 𝗧𝗮𝗯𝗹𝗲𝘀 𝗶𝗻 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀.
👇
So what is the difference between Row Based and Column Based file formats?
🧵
#Data #DataEngineering #MLOps #MachineLearning
🧵
#Data #DataEngineering #MLOps #MachineLearning
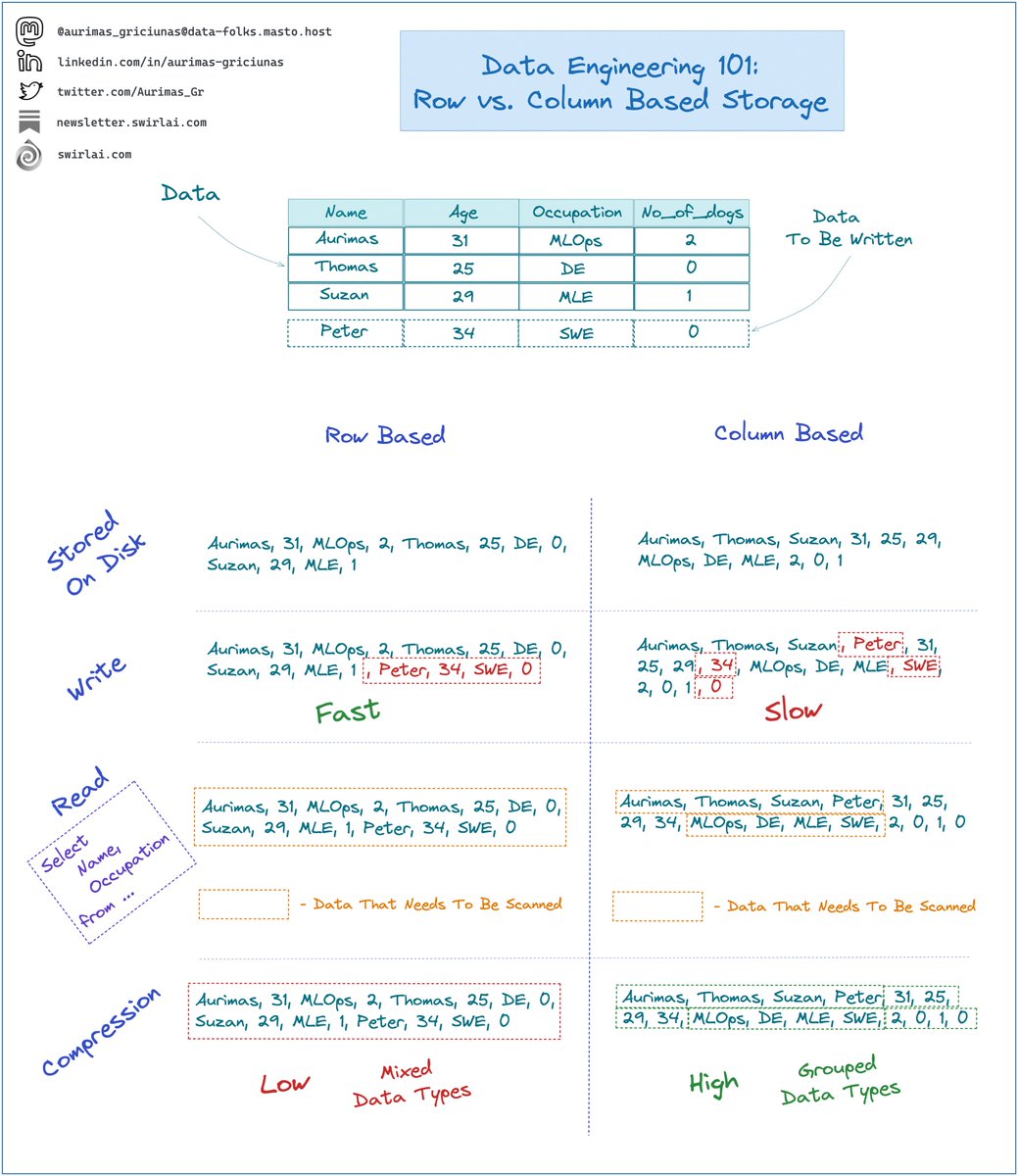
𝗥𝗼𝘄 𝗕𝗮𝘀𝗲𝗱:
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ Rows on disk are stored in sequence.
➡️ New rows are written efficiently since you can write the entire row at once.
👇
➡️ For select statements that target a subset of columns, reading is slower since you need to scan all sets of rows to retrieve one of the columns.
👇
👇
What are the main use cases for Apache Kafka or any other Distributed Messaging System?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

We have covered lots of concepts around Kafka already. But what are the most common use cases for The System that you are very likely to run into as a Data Engineer?
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗟𝗲𝘁’𝘀 𝘁𝗮𝗸𝗲 𝗮 𝗰𝗹𝗼𝘀𝗲𝗿 𝗹𝗼𝗼𝗸:
👇
𝗪𝗲𝗯𝘀𝗶𝘁𝗲 𝗔𝗰𝘁𝗶𝘃𝗶𝘁𝘆 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴.
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇
➡️ The Original use case for Kafka by LinkedIn.
➡️ Events happening in the website like page views, conversions etc. are sent via a Gateway and piped to Kafka Topics.
👇
Considering switching to a 𝗠𝗟𝗢𝗽𝘀 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿 role?
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
My thought in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Usually MLOps Engineers are professionals tasked with building out the ML Platform in the organization.
👇
👇
This means that the skill set required is very broad - naturally very few people start off with the full set of skills you would need to brand yourself as a MLOps Engineer. This is why I would not choose this role if you are just entering the market.
👇
👇
What is the difference between Splittable and Non-Splittable Files?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

You are very likely to run into a 𝗗𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝗱 𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗦𝘆𝘀𝘁𝗲𝗺 𝗼𝗿 𝗙𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 in your career. It could be 𝗦𝗽𝗮𝗿𝗸, 𝗛𝗶𝘃𝗲, 𝗣𝗿𝗲𝘀𝘁𝗼 or any other.
👇
👇
Also, it is very likely that these Frameworks would be reading data from a distributed storage. It could be 𝗛𝗗𝗙𝗦, 𝗦𝟯 etc.
👇
👇
So how do we implement 𝗣𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗚𝗿𝗮𝗱𝗲 𝗕𝗮𝘁𝗰𝗵 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗠𝗼𝗱𝗲𝗹 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 in 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
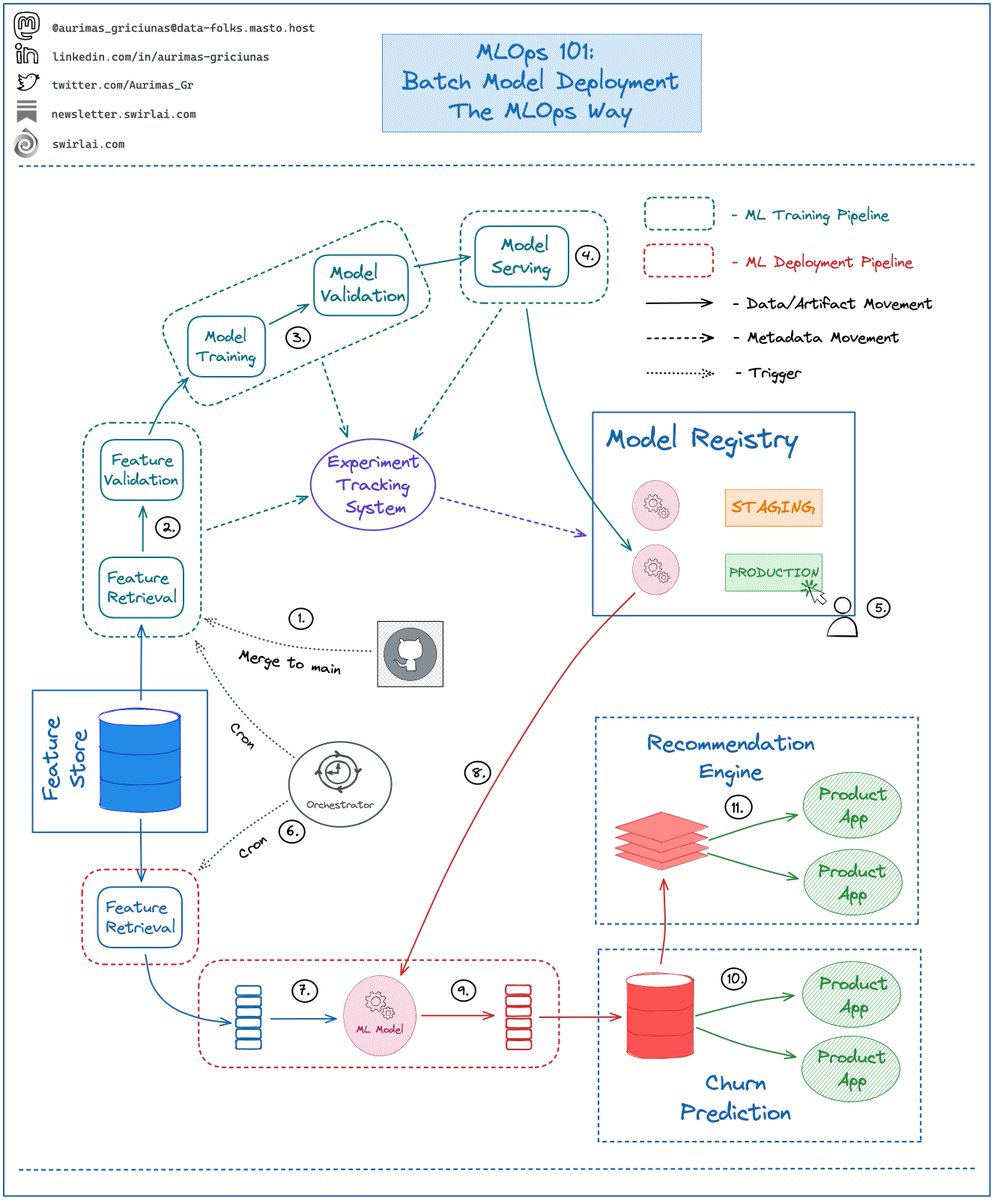
Let’s zoom in:
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟭: Everything starts in version control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟮: Feature preprocessing stage: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata is saved to an Experiment Tracking System.
👇
👇
How do we 𝗗𝗲𝗰𝗼𝗺𝗽𝗼𝘀𝗲 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗦𝗲𝗿𝘃𝗶𝗰𝗲 𝗟𝗮𝘁𝗲𝗻𝗰𝘆 and why should you care to understand the pieces as a ML Engineer?
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Usually, what is cared about by the users of your Machine Learning Service is the total endpoint latency - the time difference between when a request is performed (1.) against the Service till when the response is received (6.).
👇
👇
Certain SLAs will be established on what the acceptable latency is and you will need to reach that. Being able to decompose the total latency is even more important as you can improve each piece independently. Let's see how.
👇
👇
Do you know how 𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 𝗶𝘀 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝗲𝗱?
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Find out in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 is an extremely popular distributed processing framework utilizing in-memory processing to speed up task execution. Most of its libraries are contained in the Spark Core layer.
👇
👇
As a warm up exercise for later deeper dives and tips, today we focus on some architecture basics.
𝗦𝗽𝗮𝗿𝗸 𝗵𝗮𝘀 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝗵𝗶𝗴𝗵 𝗹𝗲𝘃𝗲𝗹 𝗔𝗣𝗜𝘀 𝗯𝘂𝗶𝗹𝘁 𝗼𝗻 𝘁𝗼𝗽 𝗼𝗳 𝗦𝗽𝗮𝗿𝗸 𝗖𝗼𝗿𝗲 𝘁𝗼 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀:
👇
𝗦𝗽𝗮𝗿𝗸 𝗵𝗮𝘀 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝗵𝗶𝗴𝗵 𝗹𝗲𝘃𝗲𝗹 𝗔𝗣𝗜𝘀 𝗯𝘂𝗶𝗹𝘁 𝗼𝗻 𝘁𝗼𝗽 𝗼𝗳 𝗦𝗽𝗮𝗿𝗸 𝗖𝗼𝗿𝗲 𝘁𝗼 𝘀𝘂𝗽𝗽𝗼𝗿𝘁 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀:
👇
A refresher on the role of 𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝘀 in the Data Pipeline.
Read on in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
Read on in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
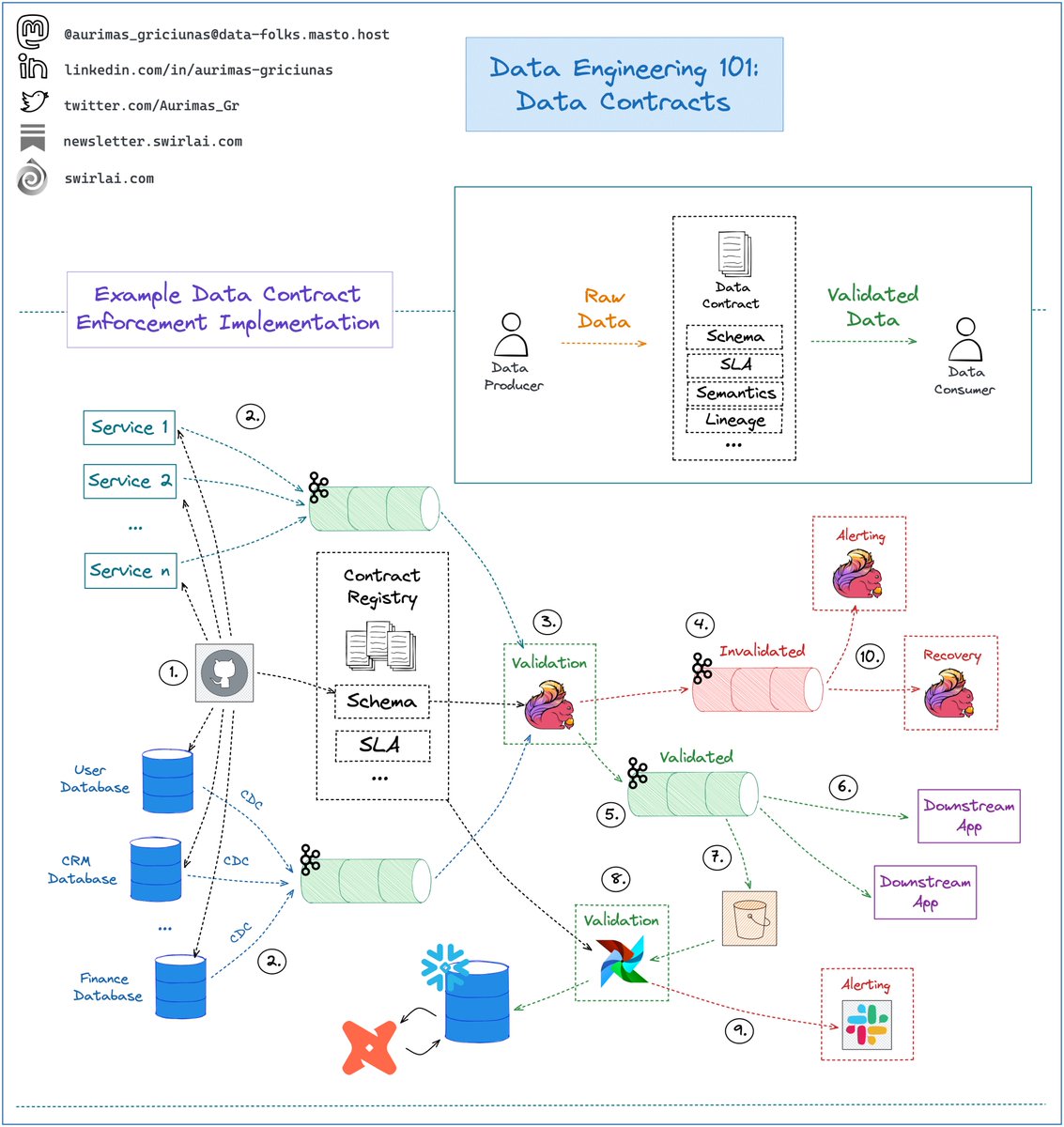
In its simplest form Data Contract is an agreement between Data Producers and Data Consumers on what the Data being produced should look like, what SLAs it should meet and the semantics of it.
👇
👇
𝗗𝗮𝘁𝗮 𝗖𝗼𝗻𝘁𝗿𝗮𝗰𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 𝗵𝗼𝗹𝗱 𝘁𝗵𝗲 𝗳𝗼𝗹𝗹𝗼𝘄𝗶𝗻𝗴 𝗻𝗼𝗻-𝗲𝘅𝗵𝗮𝘂𝘀𝘁𝗶𝘃𝗲 𝗹𝗶𝘀𝘁 𝗼𝗳 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮:
👉 Schema of the Data being Produced.
👇
👉 Schema of the Data being Produced.
👇
What does a 𝗥𝗲𝗮𝗹 𝗧𝗶𝗺𝗲 𝗦𝗲𝗮𝗿𝗰𝗵 𝗼𝗿 𝗥𝗲𝗰𝗼𝗺𝗺𝗲𝗻𝗱𝗲𝗿 𝗦𝘆𝘀𝘁𝗲𝗺 𝗗𝗲𝘀𝗶𝗴𝗻 look like?
The graph was inspired by the amazing work of @eugeneyan
More in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
The graph was inspired by the amazing work of @eugeneyan
More in the 🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Recommender and Search Systems are one of the biggest money makers for most companies when it comes to Machine Learning.
👇
👇
Both Systems are inherently similar. Their goal is to return a list of recommended items given a certain context - it could be a search query in the e-commerce website or a list of recommended songs given that you are currently listening to a certain song on Spotify.
👇
👇
Here is a short refresher on 𝗔𝗖𝗜𝗗 𝗣𝗿𝗼𝗽𝗲𝗿𝘁𝗶𝗲𝘀 𝗼𝗳 𝗗𝗕𝗠𝗦 (𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲 𝗠𝗮𝗻𝗮𝗴𝗲𝗺𝗲𝗻𝘁 𝗦𝘆𝘀𝘁𝗲𝗺).
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

It could be that you are taking ACID Properties for granted when you are using transactional databases.
If you are interviewing for Data Engineering roles you will be asked to explain what the concept means.
👇
If you are interviewing for Data Engineering roles you will be asked to explain what the concept means.
👇
Let’s take a closer look.
Transaction is a sequence of steps performed on a database as a single logical unit of work.
The ACID database transaction model ensures that a performed transaction is always consistent by ensuring:
👇
Transaction is a sequence of steps performed on a database as a single logical unit of work.
The ACID database transaction model ensures that a performed transaction is always consistent by ensuring:
👇

Artificial Intelligence is the hottest technology in 2023. Most tech companies are making new investments in AI which has created new career opportunities not just in machine learning but in MLOps as well. This thread is on career opportunities in #MLOps. RT to spread the word.👇
What is MLOps?
As companies generate and collect vast amounts of customer data, managing these large datasets and the numerous machine-learning models they create will get increasingly complex. MLOps is sometimes referred to as #AIOps as well.
As companies generate and collect vast amounts of customer data, managing these large datasets and the numerous machine-learning models they create will get increasingly complex. MLOps is sometimes referred to as #AIOps as well.
MLOps is the systematic approach to managing the entire lifecycle of ML models and their deployment in a production environment. It combines principles and practices of software engineering and #DevOps to ensure efficient, reliable, and scalable management of ML models.

Do you ever feel like your data science and IT teams are speaking different languages? That's where #MLOps comes in!
By standardizing workflows and processes, MLOps can bridge the gap between these two critical teams.
(A thread) 👇🧵
By standardizing workflows and processes, MLOps can bridge the gap between these two critical teams.
(A thread) 👇🧵
One of the key benefits of MLOps is that it enables data scientists and IT professionals to work together more efficiently and effectively. For example, MLOps practices can help to ensure that data scientists have access to the right infrastructure and tools.
Another important aspect of MLOps is that it enables data scientists to focus on what they do best – developing models and algorithms – while IT takes care of the operational aspects of model deployment and management.
𝗡𝗼 𝗘𝘅𝗰𝘂𝘀𝗲𝘀 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝗣𝗼𝗿𝘁𝗳𝗼𝗹𝗶𝗼 𝗧𝗲𝗺𝗽𝗹𝗮𝘁𝗲 - next week I will enrich it with the missing Machine Learning and MLOps parts!
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Today - let’s review it once more. It is super helpful as these kind of Data Architectures are what you will find in real life situations.
𝗥𝗲𝗰𝗮𝗽:
👇
𝗥𝗲𝗰𝗮𝗽:
👇
𝟭. Data Producers - Python Applications that extract data from chosen Data Sources and push it to Collector via REST or gRPC API calls.
👇
👇
What are 𝗟𝗮𝗺𝗯𝗱𝗮 𝗮𝗻𝗱 𝗞𝗮𝗽𝗽𝗮 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀?
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience
🧵
#Data #DataEngineering #MLOps #MachineLearning #DataScience

Lambda and Kappa are both Data architectures proposed to solve movement of large amounts of data for reliable Online access.
👇
👇
The most popular architecture has been and continues to be Lambda. However, with Stream Processing becoming more accessible to organizations of every size you will be hearing a lot more of Kappa in the near future. Let’s see how they are different.
👇
👇
Let’s remind ourselves of how a 𝗥𝗲𝗾𝘂𝗲𝘀𝘁-𝗥𝗲𝘀𝗽𝗼𝗻𝘀𝗲 𝗠𝗼𝗱𝗲𝗹 𝗗𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 looks like - 𝗧𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗪𝗮𝘆.
🧵
#MLOps #MachineLearning #DataScience #Data
🧵
#MLOps #MachineLearning #DataScience #Data

You will find this type of model deployment to be the most popular when it comes to Online Machine Learning Systems.
Let's zoom in:
𝟭: Version Control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
Let's zoom in:
𝟭: Version Control: Machine Learning Training Pipeline is defined in code, once merged to the main branch it is built and triggered.
👇
𝟮: Feature Preprocessing: Features are retrieved from the Feature Store, validated and passed to the next stage. Any feature related metadata that is tightly coupled to the Model being trained is saved to the Experiment Tracking System.
👇
👇

I have successfully compiled and run GLM-130b on a local machine! It's now running in `int4` quantization mode and answering my queries.
I'll explain the installation below; if you have any questions, feel free to ask!
github.com/THUDM/GLM-130B
I'll explain the installation below; if you have any questions, feel free to ask!
github.com/THUDM/GLM-130B
130B parameters on 4x 3090s is impressive. GPT-3 for reference is 175B parameters, but it's possible that it's over capacity for the data & compute it was trained on...
I feel like a #mlops hacker having got this to work! (Though it should be much easier than it was.)
I feel like a #mlops hacker having got this to work! (Though it should be much easier than it was.)
To get GLM to work, the hardest part was CMake from the FasterTransformer fork. I'm not a fan of CMake, I don't think anyone is.
I had to install cudnn libraries manually into my conda environment, then hack CMakeCache.txt to point to those...
I had to install cudnn libraries manually into my conda environment, then hack CMakeCache.txt to point to those...

🎁 Ding Dong! Here’s a flash from Iterative Community this month👇
🦮 MLOps Guide
🧪 DVC Extension
🌌 A Fable about MLOps
📝 Cheatsheet for DVC
🧑💻 Data Query Language
@Iterativeai @DVCorg
#mlOps #data #community
🧵[1/7]
🦮 MLOps Guide
🧪 DVC Extension
🌌 A Fable about MLOps
📝 Cheatsheet for DVC
🧑💻 Data Query Language
@Iterativeai @DVCorg
#mlOps #data #community
🧵[1/7]

🦮 MLOps Guide
For their engineering final project at @Insper, Arthur Olga, Gabriel Monteiro, Guilherme Leite, and Vinicius Lima created the MLOps Guide, which provides a Complete MLOps development cycle using DVC, CML, and IBM Watson.
mlops-guide.github.io
🧵[2/7]
For their engineering final project at @Insper, Arthur Olga, Gabriel Monteiro, Guilherme Leite, and Vinicius Lima created the MLOps Guide, which provides a Complete MLOps development cycle using DVC, CML, and IBM Watson.
mlops-guide.github.io
🧵[2/7]
🧪 DVC Extension
@erykml1 wrote a fabulous, in-depth tutorial on experiment tracking using our new DVC Extension for VS Code 👇
towardsdatascience.com/turn-vs-code-i…
🧵[3/7]
@erykml1 wrote a fabulous, in-depth tutorial on experiment tracking using our new DVC Extension for VS Code 👇
towardsdatascience.com/turn-vs-code-i…
🧵[3/7]
If I could only choose 5 books to read in 2023 as an aspiring Data Engineer these would be them in a specific order:
Read on in the Thread 👇
--------
Follow me and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
Read on in the Thread 👇
--------
Follow me and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!

1️⃣ ”𝗙𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴” - A book that I wish I had 5 years ago. After reading it you will understand the entire Data Engineering workflow. It will prepare you for further deep dives.
👇
👇
2️⃣ ”𝗔𝗰𝗰𝗲𝗹𝗲𝗿𝗮𝘁𝗲” - Data Engineers should follow the same practices that Software Engineers do and more. After reading this book you will understand DevOps practices in and out.
👇
👇
What is a 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗦𝘁𝗼𝗿𝗲 and why is it such an important element in 𝗠𝗟𝗢𝗽𝘀 𝗦𝘁𝗮𝗰𝗸?
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
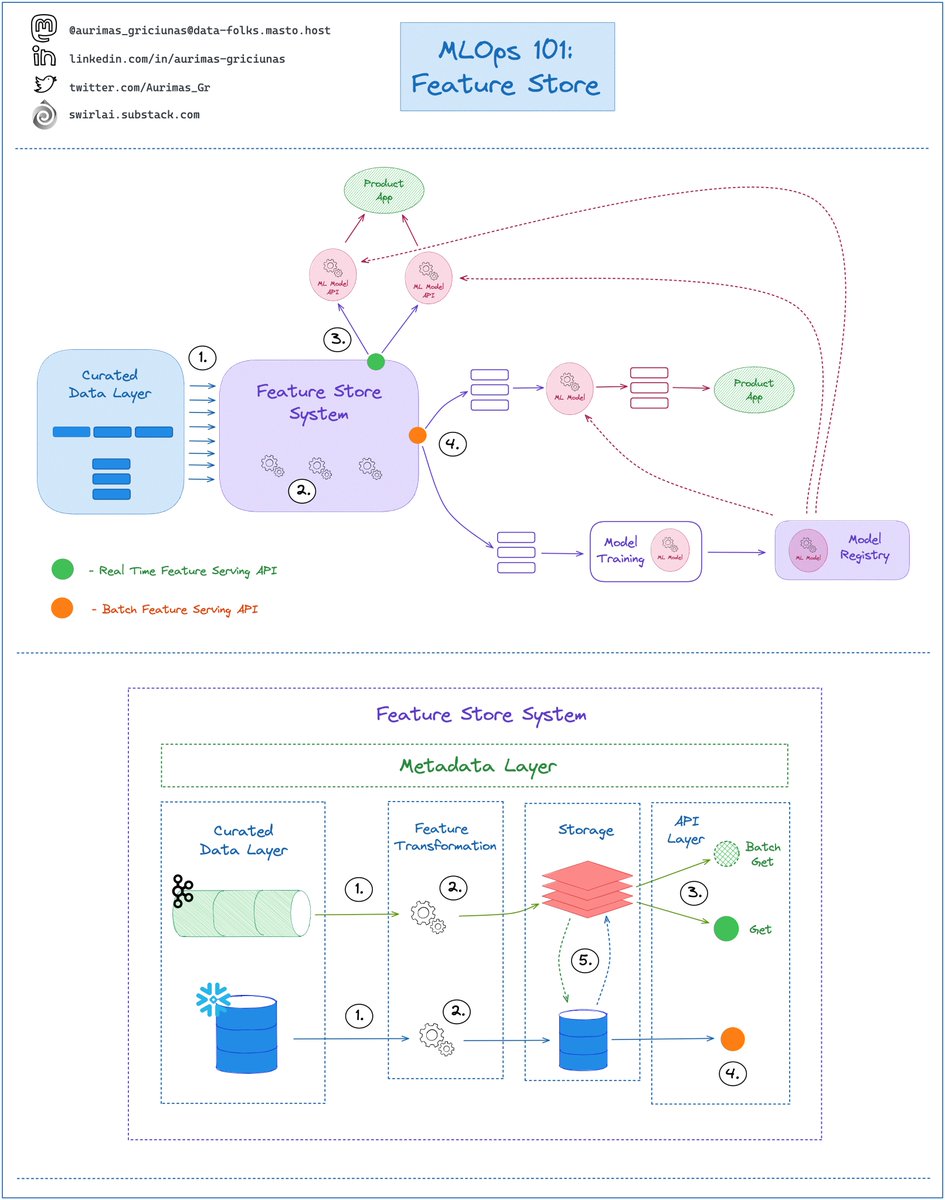
Feature Store System sits between Data Engineering and Machine Learning Pipelines and it solves the following issues:
➡️ Eliminates Training/Serving skew by syncing Batch and Online Serving Storages (5)
👇
➡️ Eliminates Training/Serving skew by syncing Batch and Online Serving Storages (5)
👇
➡️ Enables Feature Sharing and Discoverability through the Metadata Layer - you define the Feature Transformations once, enable discoverability through the Feature Catalog and then serve Feature Sets for training and inference purposes trough unified interface (4️,3).
👇
👇
Do you know what CDC(Change Data Capture) is and that there are multiple ways to implement it?
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!

𝗖𝗵𝗮𝗻𝗴𝗲 𝗗𝗮𝘁𝗮 𝗖𝗮𝗽𝘁𝘂𝗿𝗲 is a software process used to replicate actions performed against Operational Databases for use in downstream applications.
𝗧𝗵𝗲𝗿𝗲 𝗮𝗿𝗲 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀 𝗳𝗼𝗿 CDC. 𝗧𝘄𝗼 𝗼𝗳 𝘁𝗵𝗲 𝗺𝗮𝗶𝗻 𝗼𝗻𝗲𝘀:
👇
𝗧𝗵𝗲𝗿𝗲 𝗮𝗿𝗲 𝘀𝗲𝘃𝗲𝗿𝗮𝗹 𝘂𝘀𝗲 𝗰𝗮𝘀𝗲𝘀 𝗳𝗼𝗿 CDC. 𝗧𝘄𝗼 𝗼𝗳 𝘁𝗵𝗲 𝗺𝗮𝗶𝗻 𝗼𝗻𝗲𝘀:
👇
➡️ 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲 𝗥𝗲𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻 (refer to 3️⃣ in the Diagram).
👉 CDC can be used for moving transactions performed against Source Database to a Target DB. If each transaction is replicated - it is possible to retain all ACID guarantees when performing replication.
👇
👉 CDC can be used for moving transactions performed against Source Database to a Target DB. If each transaction is replicated - it is possible to retain all ACID guarantees when performing replication.
👇
What does good Model Tracking System look like?
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!
Find out in the Thread 👇
--------
𝗙𝗼𝗹𝗹𝗼𝘄 𝗺𝗲 and hit 🔔 to 𝗟𝗲𝘃𝗲𝗹 𝗨𝗽 in #MLOps, #MachineLearning, #DataEngineering, #DataScience and overall #Data space!

It should be composed of two integrated parts: Experiment Tracking System and a Model Registry.
From where you track ML Pipeline metadata will depend on MLOps maturity in your company.
If you are at the beginning of the ML journey you might be:
👇
From where you track ML Pipeline metadata will depend on MLOps maturity in your company.
If you are at the beginning of the ML journey you might be:
👇
1️⃣ Training and Serving your Models from experimentation environment - you run ML Pipelines inside of your Notebook and do that manually at each retraining.
If you are beyond Notebooks you will be running ML Pipelines from CI/CD Pipelines and on Orchestrator triggers.
👇
If you are beyond Notebooks you will be running ML Pipelines from CI/CD Pipelines and on Orchestrator triggers.
👇

Greensteam subscribed to the idea of doing #MLOps at a reasonable scale.
Seeing the quickly growing number of customers (= ML experiments), they decided to build their MLOps stack from 0 and solve all core problems around it.
Here are some of the issues → solutions:
Seeing the quickly growing number of customers (= ML experiments), they decided to build their MLOps stack from 0 and solve all core problems around it.
Here are some of the issues → solutions:
- 1000s of Jupyter notebooks → git
- Managing dependencies and reproducibility → @Docker
- Dealing with unit tests (in some parts of the model code) that don’t test → running smoke tests
- Managing dependencies and reproducibility → @Docker
- Dealing with unit tests (in some parts of the model code) that don’t test → running smoke tests
- Different linter versions showing different results locally and in Jenkins → code checks moved into Docker
- Finding parts of the code that unit tests didn’t cover → mypy
- Testing models for multiple datasets of different clients in different scenarios → @argoproj
- Finding parts of the code that unit tests didn’t cover → mypy
- Testing models for multiple datasets of different clients in different scenarios → @argoproj
