Discover and read the best of Twitter Threads about #statstwitter
Most recents (24)

Thrilled to attend a great webinar on types of research data with keynote speaker, Dr. Abdurahman Niazy from @_KSU ! Discover how our partnership was a game changer for productivity.
🙌#Statstwitter #DataScience #BioStats
🙌#Statstwitter #DataScience #BioStats

Collaboration is extremely important especially when it comes to clinical research.
- Dr. Abdurahman Niazy from @_KSU
- Dr. Abdurahman Niazy from @_KSU


This paper by @philipbstark is a must read for anyone who builds and fits statistical models as it shows how most stat models in several disciplines are insanely disconnected from reality 1/n

There are so many excellent points and examples in the paper so the rest of this thread will be screenshots with some minor annotations, first I focus on general points in the paper and then discuss the model examples which start around tweet #20 2/n

Issue: Quantifauxcation and forcing complex phenomenon into simplistic numbers for the sake of rigor and comparisons 3/n


I've been revisiting several probability, statistics & clinical research concepts that I've learned through simulation & visualization over the past years. Full list pinned below - I hope this can be helpful for others who also learn this way! #epitwitter #statstwitter #RStats
The "birthday problem"
The Monty Hall problem

I am fortunate to have an #NIH #K25 award.
In this 🧵, I will share advice about K25 awards. These opinions are my own, based on my experience, and do not represent the NIH.
Hope this helps anyone preparing a K25!
#careerdev #nihgrants #funding #statstwitter #epitwitter 1/
In this 🧵, I will share advice about K25 awards. These opinions are my own, based on my experience, and do not represent the NIH.
Hope this helps anyone preparing a K25!
#careerdev #nihgrants #funding #statstwitter #epitwitter 1/
Who should apply for a K25 award?
K25s are for quantitative experts seeking training in a new clinical area. These are perfect for (bio)statisticians starting in a faculty role pivoting to a new area that aligns with their institution.
K25s cover 75% FTE for up to 5 years. 2/
K25s are for quantitative experts seeking training in a new clinical area. These are perfect for (bio)statisticians starting in a faculty role pivoting to a new area that aligns with their institution.
K25s cover 75% FTE for up to 5 years. 2/
⭐️Most important advice in this thread⭐️
Include a figure connecting your career goals, proposed training, mentor expertise, and research aims.
The next career step should be submitting an R01 and becoming an independent scientist in the new clinical field. 3/
Include a figure connecting your career goals, proposed training, mentor expertise, and research aims.
The next career step should be submitting an R01 and becoming an independent scientist in the new clinical field. 3/


I'm a doctor who does research.
I've annoyed DOZENS of statisticians.
Here are 5 proven ways to exasperate them.
#medtwitter #epitwitter #statstwitter
I've annoyed DOZENS of statisticians.
Here are 5 proven ways to exasperate them.
#medtwitter #epitwitter #statstwitter
1. Start every request for help with, "I know the p-value is the probability the null hypothesis is true..."
Then when they start to object, roll right into your request. "...so can you find smaller p-values?" or something along those lines.
Works every time.
Then when they start to object, roll right into your request. "...so can you find smaller p-values?" or something along those lines.
Works every time.
2. Make spreadsheets as bright and creative as possible
Use lots of colors, alternate between three date formats, be liberal with random capitals in column names, use free text answers, encourage puns.
Also, be sure to say "have fun with the analysis" when you hand it over.
Use lots of colors, alternate between three date formats, be liberal with random capitals in column names, use free text answers, encourage puns.
Also, be sure to say "have fun with the analysis" when you hand it over.

Hi #EpiTwitter, #AcademicTwitter, #StatsTwitter, #JobSeakers:
I am currently searching for a postdoc and 2 data analysts (postings below). I want to make the case for why these opportunities may be a great fit for you.
I am currently searching for a postdoc and 2 data analysts (postings below). I want to make the case for why these opportunities may be a great fit for you.
Argument 1: The analyses we’re working on are fascinating, novel, and all aim to reduce health inequities.
(disclaimer: I may not be an unbiased source on whether the work I do is interesting)
1.1
(disclaimer: I may not be an unbiased source on whether the work I do is interesting)
1.1

Geçmiş yarım yüzyıldaki önemli istatistiksel gelişmeleri konu eden bir makaleye rastladım.
Önemli bir kaç noktayı sizlerle paylaşmak isterim 🧵
#statstwitter
Önemli bir kaç noktayı sizlerle paylaşmak isterim 🧵
#statstwitter

1⃣ Makale iki yazar tarafından kaleme alınmış olsa da, süreçte farklı isimlerden öneriler alındığının altı çiziliyor. İlk olarak sandığımızdan daha geniş bir bakış açışıyla yazıldığını söylemeliyim.
2⃣ Bu dönemde öne çıkan 8 popüler konu:
• Karşı-olgusal nedensel çıkarım
• Simülasyonel çıkarım
• Çok parametreli modeller & düzenlileştirme
• Çok düzeyli Bayesyen modeller
• Hesaplama algoritmaları
• Uyarlanabilir karar analizi
• Sağlam çıkarım
• Açıklayıcı veri analizi
• Karşı-olgusal nedensel çıkarım
• Simülasyonel çıkarım
• Çok parametreli modeller & düzenlileştirme
• Çok düzeyli Bayesyen modeller
• Hesaplama algoritmaları
• Uyarlanabilir karar analizi
• Sağlam çıkarım
• Açıklayıcı veri analizi

Hi @FrontiersIn : A paper of yours (editor: @GetchellNancy) missed some very important (and honestly basic) statistical issues, and is contributing to a narrative that is not supported by the paper.
#twitterpeerreview
#reviewer2stepsinanddoesthejob
#statstwitter
#twitterpeerreview
#reviewer2stepsinanddoesthejob
#statstwitter
The paper should have been challenged on review:
* why not iterate 1 year vs other 5 years for all years '16-20 (resolves all issues)
* why not challenge the finding in "communication at 1 year" increasing for 2020 when clearly the significance comes from the low 2017 #
/2
* why not iterate 1 year vs other 5 years for all years '16-20 (resolves all issues)
* why not challenge the finding in "communication at 1 year" increasing for 2020 when clearly the significance comes from the low 2017 #
/2
Had it done so, the conclusion of the paper would be markedly different: "2020 showed similar and expected fluctuations as has been seen in the prior 5 years in all domains," and it would not be used as evidence that "pandemic measures effects harm child development"
/3
/3

We are getting ready, here.
Looking forward to hearing what's been going on in @NHSDigital
👍👍👍👍
@RoyalStatSoc
Looking forward to hearing what's been going on in @NHSDigital
👍👍👍👍
@RoyalStatSoc

Chris Roebuck from @NHSDigital kicked us off with an introduction to and summary of NHS Digital’s role generally and specifically in relation to the COVID situation.
Don't worry, the session is being recorded and is running with a streamed transcript for accessibility.
Don't worry, the session is being recorded and is running with a streamed transcript for accessibility.

Sharon Thandi begins with a discussion about a follow-up survey about #mentalhealth that started in 2017


First, PRIORS. In Bayesian Statistics, we use probability distributions (like a normal, Cauchy, beta...) to represent uncertainty about the value of parameters.
Instead of choosing ONE number for a param, a distribution describes how likely a range of values are
Instead of choosing ONE number for a param, a distribution describes how likely a range of values are

Bayesian Stats works by taking previously known, PRIOR information (this can be from prior data, domain expertise, regularization...) about the parameter
and combining it with data to make the POSTERIOR (the distribution of parameter values AFTER including data)
and combining it with data to make the POSTERIOR (the distribution of parameter values AFTER including data)


1/ Readers ask: What's the simplest problem in which a combination of experimental and observational studies can be shown to be better than each study alone?
Ans. Consider X--->Z----> Y
with unobserved confounder between X & Z.
Query Q: Find P(y|do(x))
We have 2 valid estimands:
Ans. Consider X--->Z----> Y
with unobserved confounder between X & Z.
Query Q: Find P(y|do(x))
We have 2 valid estimands:
2/
ES1 = P(y|do(x)) estimable from the experiment
ES2 =SUM_z P(z|do(x))P(y|z), the first term is estimable from the experiment, the second from the observational study.
ES2 is better than ES1 for 3 reasons:
1. P(y|z) can rest on a larger sample
2. ES2 is composite (see
ES1 = P(y|do(x)) estimable from the experiment
ES2 =SUM_z P(z|do(x))P(y|z), the first term is estimable from the experiment, the second from the observational study.
ES2 is better than ES1 for 3 reasons:
1. P(y|z) can rest on a larger sample
2. ES2 is composite (see
3/ (see ucla.in/2ocoWqq for advantage of composite estimators)
3. ES2 need not measure Y in the experimental study.
Remark: The validity of ES2 follows from do-calculus. Adding any edge to the graph invalidates ES2 and leaves ES1 the only estimand.
3. ES2 need not measure Y in the experimental study.
Remark: The validity of ES2 follows from do-calculus. Adding any edge to the graph invalidates ES2 and leaves ES1 the only estimand.

New paper alert🚨#statstwitter
Conformal inference, often framed as a technique to generate prediction intervals, is also a tool for out-of-distribution detection. We studied marginal/conditional conformal p-values for multiple testing with marginal/conditional error control 1/n
Conformal inference, often framed as a technique to generate prediction intervals, is also a tool for out-of-distribution detection. We studied marginal/conditional conformal p-values for multiple testing with marginal/conditional error control 1/n
We consider the setting where a dataset of “inliers” is available. Existing outlier detection algorithms often output a “score” for each testing point indicating how regular it is.
But how to choose a cutoff to get guaranteed statistical error (e.g., type-I error) control? 2/n
But how to choose a cutoff to get guaranteed statistical error (e.g., type-I error) control? 2/n

For a single data point X, it can be formulated as a hypothesis testing problem with H0: X~P, where P is the (unknown) distribution of inliers X_1, …, X_n. Intuitively, H0 should be rejected if score(X) is too small compared to {score(X_1), …, score(X_n)}. 3/n
People are often asking me for the data, so here we go. Overall, in jurisdictions that have reported numbers so far, Canadian suicide rates are down 16.8% in 2020 compared to 2019.
An awful year.
But, fortunately, there have been less suicides.
#statstwitter #epitwitter
An awful year.
But, fortunately, there have been less suicides.
#statstwitter #epitwitter

quick correction. Saskatchewan suicide rates are much lower than expected variance.
*************
Variance 🧵:
Why the media (and non-experts who "dabble" in mortality statistics) particularly suck at reporting the numbers of suicide
**************
Quite frequently, someone will send me an article like this.
#epitwitter #statstwitter
Variance 🧵:
Why the media (and non-experts who "dabble" in mortality statistics) particularly suck at reporting the numbers of suicide
**************
Quite frequently, someone will send me an article like this.
#epitwitter #statstwitter

1/ Suicides are up 67% between the ages of 12-17 in Pima County.
By "mid-Nov 20", there have been 43 teen suicides, compared to 38 in total last year!
Without context, it certainly seems that the pandemic or the lockdown is to blame.
By "mid-Nov 20", there have been 43 teen suicides, compared to 38 in total last year!
Without context, it certainly seems that the pandemic or the lockdown is to blame.

2/ Sure enough, i go to @CDC Wonder and fire up Arizona suicides for 2019 between 12-17 and I see there were 36 suicides in 2019 (not sure why there is a discrepancy between AZ DOH and CDC, but this is actually common by about 5%ish).

Wanna become a data scientist?
Sᴛᴇᴘ 1: ɢᴇᴛ ᴅᴀᴛᴀ.
Sᴛᴇᴘ 2: ᴅᴏ sᴄɪᴇɴᴄᴇ.
Sᴛᴇᴘ 1: ɢᴇᴛ ᴅᴀᴛᴀ.
Sᴛᴇᴘ 2: ᴅᴏ sᴄɪᴇɴᴄᴇ.
Alternatively:
Step 1: Think about becoming a lawyer but ditch that because you can’t stand foreign political history classes. Add a philosophy double major because sureee that’ll help🙄. Then switch to psychology, meet an awesome statistician and decide you love statistics
Step 1: Think about becoming a lawyer but ditch that because you can’t stand foreign political history classes. Add a philosophy double major because sureee that’ll help🙄. Then switch to psychology, meet an awesome statistician and decide you love statistics
in your last semester of college.
graduate. Work in a cognitive neuroscience lab while living at home, apply to data science grad programs, get rejected by Berkeley, get into Chapman university, find an advisor who needs someone with stats AND psych expertise,
graduate. Work in a cognitive neuroscience lab while living at home, apply to data science grad programs, get rejected by Berkeley, get into Chapman university, find an advisor who needs someone with stats AND psych expertise,

We dove into how financial incentives affect hospital participation in BPCI-Advanced and what this means for CMS.
Hospitals with higher spending targets are:
1. More likely to participate
2. More likely to gain shared savings from mean reversion
bit.ly/32bVrKd
Hospitals with higher spending targets are:
1. More likely to participate
2. More likely to gain shared savings from mean reversion
bit.ly/32bVrKd


This is important because the vast majority of alternative payment models are VOLUNTARY.
Thus, burden falls on CMS to design incentives that encourage participation while achieving meaningful reductions in spending.
Key articles on this topic below:
Thus, burden falls on CMS to design incentives that encourage participation while achieving meaningful reductions in spending.
Key articles on this topic below:


The main research project from my postdoc just got published in Human Reproduction: cost-effectiveness of medically assisted reproduction for unexplained subfertility. tinyurl.com/y36hkrbs (open access)
Time for a tweetorial on cost-effectiveness!
#epitwitter #statstwitter
Time for a tweetorial on cost-effectiveness!
#epitwitter #statstwitter
Thinking of our health care in terms of finances can come across as cold and calculating. Unfortunately we do not have infinite amounts of medical staff and hospital beds. The harsh truth is that we DO have to make choices, for instance more effective or less expensive treatments
In practice, we often encounter the situation that a (new) treatment seems more effective but also more expensive than usual care or control. This constitutes a decision problem: is it ‘worth’ to set the more expensive treatment as the new standard of care?

NEW(-ish) PAPER
Ever wanted to harness repeatedly-measured predictors within a clinical prediction model but found the existing literature overwhelming?
Look no further, our recent methodological review can help! 👇👇👇
#epitwitter #statstwitter #phdchat #epidemiology
Ever wanted to harness repeatedly-measured predictors within a clinical prediction model but found the existing literature overwhelming?
Look no further, our recent methodological review can help! 👇👇👇
#epitwitter #statstwitter #phdchat #epidemiology

💡 To make this field more accessible for applied researchers, the extracted modelling techniques were grouped based on similarity, and how they used repeated observations to enhance prediction. 💡
The three main motivations to incorporate repeatedly-measured predictors were:
1⃣ To improve model specification and applicability over time
2⃣ To infer an error-free predictor value at a pre-specified time
3⃣ To account for the effects of predictor change over time
1⃣ To improve model specification and applicability over time
2⃣ To infer an error-free predictor value at a pre-specified time
3⃣ To account for the effects of predictor change over time

Was asked for personal favorite resources for improving methods and statistics skills. I promised to make it a thread, so here it is
1/n
1/n
I work in medical research, so that is going to be my focus here too. But I’d like to think the resources are relevant to a wider audience
This list should not be taken as a guide to become a statistician, nor is it a must-read list for all academics (obviously)
2/n
This list should not be taken as a guide to become a statistician, nor is it a must-read list for all academics (obviously)
2/n
My personal view is that medical research would benefit from involving trained statisticians earlier and more frequently; not from everyone trying to become one
Here are some good arguments by @statsepi:
medium.com/@darren_dahly/…
And some more: medium.com/@darren_dahly/…
3/n
Here are some good arguments by @statsepi:
medium.com/@darren_dahly/…
And some more: medium.com/@darren_dahly/…
3/n

1. Why do some #COVID19 cases have severe outcomes while others are mild? Many of the comorbidities associated with poor outcomes are also associated with #obesity. A new paper looks even deeper to find an underlying link ==> chronic inflammation nature.com/articles/s4136…
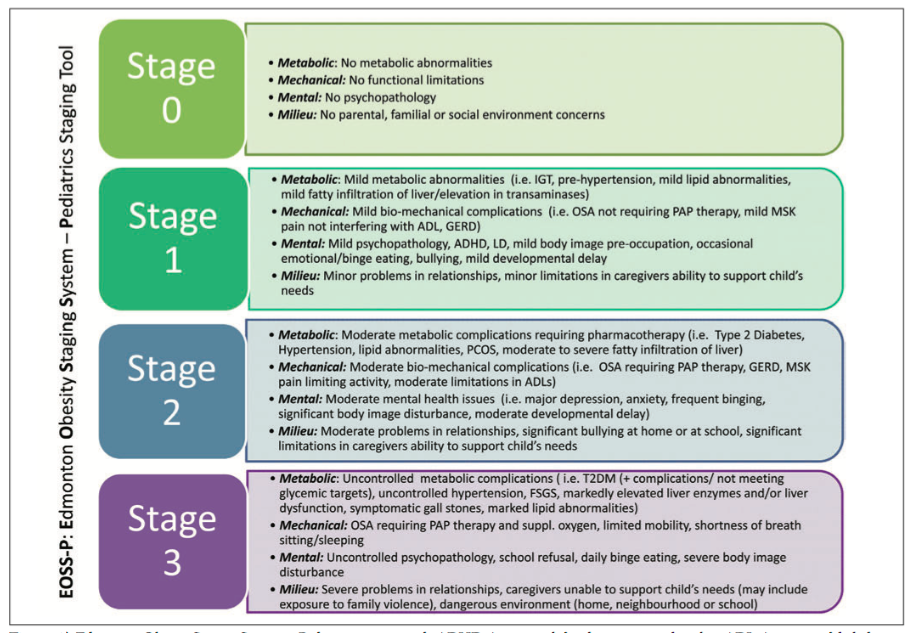
2. The authors of this paper are familiar with how one size does not fit all with obesity. @DrSharma established the Edmonton Obesity Staging System to help characterize obesity beyond size alone to address physical, mental, and functional health. drsharma.ca/wp-content/upl…
3. The authors identify age-dependent defects in T-cell and B-cell function and the excess production of type 2 cytokines could lead to a deficiency in control of viral replication and more prolonged pro-inflammatory responses, potentially leading to poor outcome

Are you a neonatologist, hematologist, transfusion expert, epidemiologist or statistician and interested in neonatal transfusion research? Contact me and join a neonatal transfusion network in-the-making. Trainees and ECR welcome. @EBNEO @blooducation #epitwitter #statstwitter
I forgot to mention a very important group: fundamental researchers are also invited to join.
Wow, lots of response. Perhaps good to clarify that we will have quite a strong focus on Europe, but ofcourse are open to participants from all over the world.

This piece on #SARSCoV2 viral load in children and adults has been highly influential.
Can you extrapolate from “Data on viral load” that “we have to caution against an unlimited re-opening of schools and kindergartens in the present situation”
I have serious concerns. 1/7
Can you extrapolate from “Data on viral load” that “we have to caution against an unlimited re-opening of schools and kindergartens in the present situation”
I have serious concerns. 1/7

There are two issues: science and politics
On the science
1. There is no methods section about how study population was selected and who they represent
– yes, I know it is a bunch of samples tested in a virology lab - with no denominators about how many samples tested by age 2/7
On the science
1. There is no methods section about how study population was selected and who they represent
– yes, I know it is a bunch of samples tested in a virology lab - with no denominators about how many samples tested by age 2/7
2. The very low number of samples from children already says a lot about selection into the study. There is no information about their clinical characteristics, stage of infection, etc.
And unequal numbers across the groups makes them very difficult to compare, even visually 3/7
And unequal numbers across the groups makes them very difficult to compare, even visually 3/7

Ok. Just spotted this in NEJM.
nejm.org/doi/full/10.10…
Any #EBMtwitter #epitwitter #statstwitter convos on it yet?
If not let’s start it here #RCT_RWE
nejm.org/doi/full/10.10…
Any #EBMtwitter #epitwitter #statstwitter convos on it yet?
If not let’s start it here #RCT_RWE
https://t.co/1E6h8YmSy6

Hello #epitwitter and #statstwitter,
There was a recent discussion about the Hosmer-Lemeshow goodness of fit test. I thought it would be interesting to talk to Dr. Lemeshow (who is not on twitter) about his thoughts on the test. This thread has some highlights from our chat. 1/n
There was a recent discussion about the Hosmer-Lemeshow goodness of fit test. I thought it would be interesting to talk to Dr. Lemeshow (who is not on twitter) about his thoughts on the test. This thread has some highlights from our chat. 1/n
In the late 70’s, Hosmer and Lemeshow were struggling with the question “How do you know that the probabilities produced by logistic regression models reflect reality?” This was the motivation for developing the Hosmer-Lemeshow goodness of fit test. 2/n
As with a linear regression, we can’t only look at the estimates from the model to know if the fit is good. For linear regression we can look at a plot (e.g., residual plot) to assess model fit. 3/n

{kind=link}